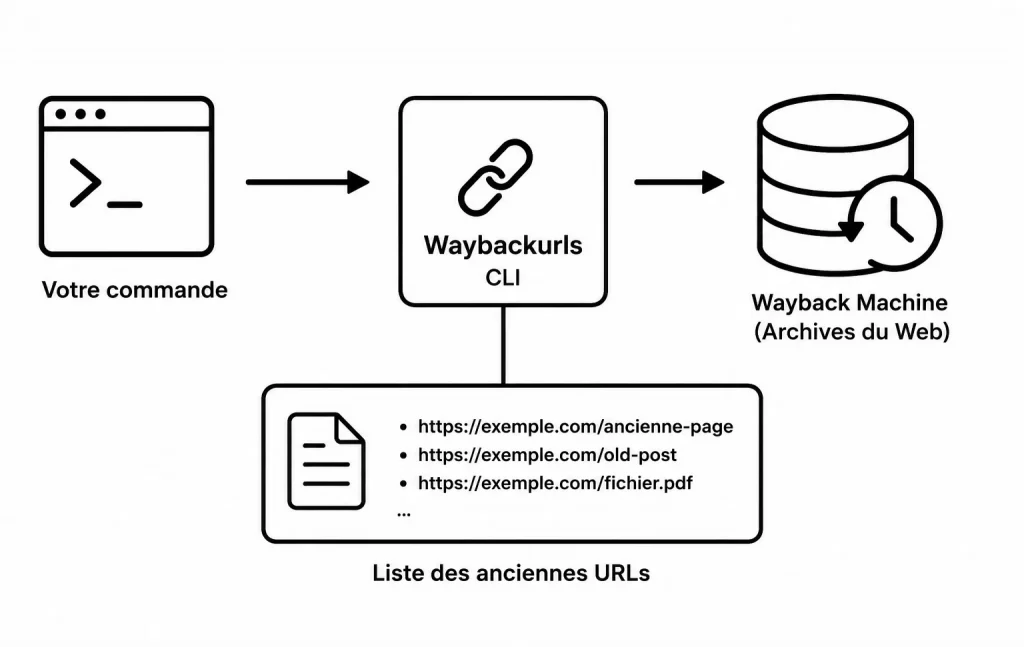
Vous souhaitez découvrir les anciennes URLs d’un site web, retrouver des pages supprimées ou analyser l’historique d’un domaine ? Waybackurls est un outil en ligne de commande simple et redoutablement efficace qui permet d’explorer les archives de la Wayback Machine en quelques secondes.
Dans ce guide, vous apprendrez à installer et utiliser Waybackurls CLI, à récupérer des URLs archivées, à filtrer les résultats les plus pertinents et à exploiter ces informations. Même si vous débutez avec le terminal, vous verrez qu’il suffit de quelques commandes pour commencer à révéler le passé d’un site.
- Retrouver des pages, fichiers et ressources oubliés grâce aux archives du Web pour mieux comprendre l’historique d’un site.
- Gagner du temps avec des commandes simples permettant d’identifier rapidement les URLs les plus intéressantes parmi des centaines de résultats.
- Développer une méthode d’analyse utile pour le SEO, le développement web et les audits techniques sans avoir besoin d’être expert du terminal.
Quand on analyse un site web, on pense souvent aux pages visibles aujourd’hui : l’accueil, les articles, les catégories, les formulaires, les fichiers CSS ou JavaScript actuellement en ligne. Pourtant, Internet garde une mémoire. Des pages supprimées, d’anciennes URLs, de vieux paramètres, des fichiers oubliés ou des chemins techniques peuvent encore apparaître dans les archives du Web.
C’est précisément là que Waybackurls devient intéressant. Cet outil en ligne de commande permet de récupérer les URLs historiques connues par la Wayback Machine pour un domaine donné. Dit autrement, vous lui donnez un nom de domaine, et il part interroger les archives pour ressortir une liste d’adresses que le site a pu utiliser dans le passé.
Vous allez apprendre à comprendre ses résultats, à filtrer les URLs utiles et à l’intégrer dans une méthode d’analyse. Pas besoin d’être expert en cybersécurité ou en terminal. On va avancer tranquillement, comme en formation, avec des exemples concrets et des commandes commentées.
- Qu’est-ce que Waybackurls ?
- Pourquoi c'est utilisé en Pentest ?
- Installer Waybackurls
- Première utilisation de Waybackurls
- Enregistrer les résultats dans un fichier
- Utiliser Waybackurls avec plusieurs domaines
- Filtrer les résultats avec grep
- Tester si les URLs répondent encore
- Comprendre les limites de Waybackurls
- Créer un petit script Bash
- Lire les résultats intelligemment
- Waybackurls et WordPress
- Différence entre Waybackurls et un crawler
- Commandes utiles à retenir
Qu’est-ce que Waybackurls ?
Waybackurls est un outil en ligne de commande, aussi appelé outil CLI. CLI signifie Command Line Interface, ou interface en ligne de commande en français. Au lieu de cliquer sur des boutons dans une interface graphique, vous tapez des commandes dans un terminal.
Son rôle est simple : récupérer les URLs archivées d’un domaine depuis la Wayback Machine, le service d’archivage web proposé par Internet Archive.
Imaginez que votre site soit une maison. Aujourd’hui, vous voyez la façade actuelle : les pièces existantes, les portes ouvertes, les fenêtres propres. Mais Waybackurls, lui, va fouiller les anciennes photos de la maison. Il peut retrouver une ancienne porte condamnée, une extension supprimée ou une pièce qui a existé il y a plusieurs années. C’est cette mémoire historique qui rend l’outil intéressant.
Concrètement, Waybackurls peut retrouver des adresses comme :
https://exemple.com/ancienne-page
https://exemple.com/admin-test
https://exemple.com/api/users?id=12
https://exemple.com/wp-content/uploads/ancien-fichier.pdfAttention cependant : retrouver une URL ne signifie pas forcément qu’elle existe encore aujourd’hui. Certaines pages peuvent être supprimées, redirigées ou protégées. Waybackurls vous donne une liste de pistes, pas une vérité absolue.
À quoi sert Waybackurls ?
Waybackurls est souvent utilisé dans le domaine de la reconnaissance web, de l’audit technique, du SEO et de la sécurité défensive.
Pour un développeur ou un webmaster, il peut servir à retrouver d’anciennes pages oubliées. Par exemple, si vous avez changé la structure de votre site il y a plusieurs années, certaines URLs peuvent encore traîner dans les archives. Cela peut vous aider à créer de meilleures redirections, nettoyer votre contenu ou comprendre l’historique d’un site.
Pour le SEO, Waybackurls peut être pratique pour retrouver d’anciennes pages qui ont peut-être reçu des liens externes. Une URL supprimée mais encore citée ailleurs peut représenter une opportunité : vous pouvez la rediriger vers une page actuelle pertinente au lieu de laisser vos visiteurs tomber sur une erreur 404.
En cybersécurité défensive, l’outil permet aussi d’identifier d’anciens chemins sensibles : anciens formulaires, anciens endpoints d’API, fichiers de test, pages d’administration ou paramètres visibles dans les URLs. Là encore, l’objectif doit rester propre et légal : analyser vos propres sites, vos environnements de test ou des périmètres pour lesquels vous avez une autorisation.
Osint ou Pentest
waybackurls se situe exactement à l’intersection des deux : c’est un outil d’OSINT utilisé pour la phase de reconnaissance d’un Pentest (ou en Bug Bounty).
Pour faire simple, c’est de l’OSINT par sa méthode, et du Pentest par son objectif.
Pourquoi c’est de l’OSINT ?
L’OSINT (Open Source Intelligence ou Renseignement d’Origine Source Ouverte) consiste à collecter des informations à partir de sources publiques et accessibles à tous.
- Zéro contact avec la cible : Quand vous utilisez
waybackurls, vous n’envoyez aucun paquet et aucune requête aux serveurs de l’entreprise visée. - Interrogation d’un tiers : L’outil va uniquement interroger les serveurs de la Wayback Machine (Internet Archive) pour lui demander : « Qu’est-ce que tu as en mémoire sur ce site ? »
- Reconnaissance passive : C’est l’essence même de l’OSINT. Votre démarche est 100 % indétectable par la cible.
Pourquoi c’est utilisé en Pentest ?
Dans un test d’intrusion (Pentest), la toute première étape est la reconnaissance (ou recon). Avant d’attaquer, il faut cartographier la cible. C’est là que waybackurls devient une mine d’or pour un auditeur ou un hacker éthique.
En récupérant l’historique de toutes les URL indexées par le passé, un pentester cherche des failles logiques ou des oublis :
- Des endpoints d’API obsolètes ou cachés : Par exemple, une ancienne version d’une API (
/api/v1/debug) qui n’est plus liée nulle part sur le site actuel, mais qui tourne toujours en arrière-plan et qui est moins sécurisée. - Des fichiers sensibles oubliés : Des fichiers de configuration (
.env,.git), des sauvegardes (.bak,.zip) ou des fichiers de traitement de données. - Des paramètres de requêtes : Trouver des URL du type
?id=10ou?file=testdonne des indices précieux sur les paramètres à tester pour des failles d’injection (SQLi) ou d’inclusion de fichiers (LFI). - Des scripts JavaScript anciens : En analysant de vieux fichiers
.js, on trouve parfois des clés d’API, des commentaires de développeurs ou des identifiants laissés par erreur.
En résumé, si on devait lui coller une étiquette précise, c’est un outil de reconnaissance passive pour la sécurité offensive.
Avant de commencer : les prérequis
Waybackurls est écrit en Go. Pour l’installer simplement, vous devez donc avoir Go installé sur votre ordinateur.
Go est un langage de programmation, mais rassurez-vous : vous n’avez pas besoin d’apprendre Go pour utiliser Waybackurls. Il sert seulement à installer l’outil.
Pour vérifier si Go est déjà installé, ouvrez votre terminal et tapez :
go versionSi Go est installé, vous devriez voir une réponse ressemblant à ceci :
go version go1.22.0 darwin/amd64La version exacte peut être différente. Ce n’est pas grave.
Si le terminal répond que la commande go est introuvable, cela signifie que Go n’est pas encore installé sur votre machine. Dans ce cas, installez Go depuis le site officiel, ou via homebrew :
brew install goInstaller Waybackurls
Une fois Go installé, l’installation de Waybackurls se fait avec une seule commande :
go install github.com/tomnomnom/waybackurls@latestPrenons le temps de comprendre cette commande.
La partie go install demande à Go d’installer un programme. Ensuite, github.com/tomnomnom/waybackurls indique où se trouve le code source de l’outil. Enfin, @latest signifie que vous voulez installer la dernière version disponible.
Après l’installation, testez la commande suivante :
waybackurlsSi rien ne s’affiche ou si le terminal attend une entrée, c’est plutôt bon signe. Waybackurls fonctionne principalement avec des domaines envoyés en entrée.
En revanche, si vous obtenez une erreur du type :
command not found: waybackurlscela signifie souvent que le dossier contenant les programmes Go n’est pas dans votre variable PATH.
Corriger l’erreur “command not found”
Sur macOS ou Linux, les programmes installés avec Go se trouvent souvent dans ce dossier :
~/go/binPour vérifier si Waybackurls s’y trouve, tapez :
ls ~/go/binSi vous voyez waybackurls dans la liste, l’outil est bien installé. Votre terminal ne sait simplement pas encore où le trouver.
Vous pouvez ajouter ce dossier à votre PATH avec cette commande :
export PATH=$PATH:~/go/binCette commande fonctionne pour la session actuelle du terminal. Pour rendre le changement permanent, ajoutez-la à votre fichier de configuration shell.
Si vous utilisez Zsh, très courant sur macOS récent :
echo 'export PATH=$PATH:~/go/bin' >> ~/.zshrc
source ~/.zshrcSi vous utilisez Bash :
echo 'export PATH=$PATH:~/go/bin' >> ~/.bashrc
source ~/.bashrcEnsuite, testez à nouveau :
waybackurlsÀ ce stade, votre terminal devrait reconnaître la commande.
Première utilisation de Waybackurls
La manière la plus simple d’utiliser Waybackurls consiste à envoyer un domaine avec echo.
echo "example.com" | waybackurlsDécomposons cette commande.
- La partie
echo "example.com"affiche simplement le texteexample.com. - Le symbole
|, appelé pipe, envoie ce résultat à la commande suivante. - Enfin,
waybackurlsrécupère ce domaine et recherche les URLs archivées associées.
Vous pouvez voir le pipe comme un tuyau. À gauche, on met quelque chose dans le tuyau. À droite, un autre outil le reçoit et le traite. C’est une des grandes forces du terminal : les commandes peuvent travailler ensemble comme une petite équipe bien organisée.
Le résultat peut ressembler à ceci :
http://example.com/
https://example.com/about
https://example.com/contact
https://example.com/assets/app.js
https://blog.example.com/old-post
...Chaque ligne correspond à une URL trouvée dans les archives.
Enregistrer les résultats dans un fichier
Quand vous analysez un domaine, la sortie peut être très longue. Au lieu de laisser toutes les URLs défiler dans le terminal comme un générique de film interminable, vous pouvez les enregistrer dans un fichier.
echo "example.com" | waybackurls > urls.txtLe symbole > redirige la sortie vers un fichier. Ici, au lieu d’afficher les résultats dans le terminal, la commande les écrit dans urls.txt.
Vous pouvez ensuite ouvrir ce fichier avec un éditeur de texte, ou l’afficher dans le terminal :
cat urls.txtLa commande cat affiche le contenu d’un fichier.
Utiliser Waybackurls avec plusieurs domaines
Waybackurls accepte aussi plusieurs domaines, à condition de les fournir ligne par ligne.
Créez un fichier domains.txt avec Nano, l’éditeur de fichier du terminal :
nano domains.txtAjoutez par exemple :
example.com
blog.example.com
shop.example.comEnregistrez le fichier, puis lancez :
cat domains.txt | waybackurls > urls.txtIci, cat domains.txt lit la liste des domaines, puis le pipe envoie chaque ligne à Waybackurls. Le résultat complet est enregistré dans urls.txt.
Cette méthode est très pratique si vous analysez plusieurs sous-domaines ou plusieurs sites que vous administrez.
Filtrer les résultats avec grep
Waybackurls peut produire beaucoup de résultats. Certains seront très utiles, d’autres beaucoup moins. Pour trier tout cela, on peut utiliser grep.
grep est une commande qui permet de chercher du texte dans une sortie ou dans un fichier. Par exemple, pour afficher uniquement les URLs contenant .php :
cat urls.txt | grep ".php"Cette commande lit le fichier urls.txt, puis conserve uniquement les lignes contenant .php.
Vous pouvez aussi chercher les URLs qui contiennent un point d’interrogation. C’est intéressant, car les URLs avec ?utilisent souvent des paramètres.
cat urls.txt | grep "?"Exemple de résultat :
https://example.com/product.php?id=42
https://example.com/search?q=formation
https://example.com/page?category=webLes paramètres sont les morceaux situés après le ?. Ils servent souvent à transmettre une information à une page : un identifiant, une recherche, une catégorie, une pagination, etc.
👉 pour aller plus loin en pentesting, utiliser DalFox ou Owasp Zap pour dénicher une faille xss.
Rechercher les fichiers JavaScript
Les fichiers JavaScript sont particulièrement intéressants lors d’un audit technique. Ils peuvent révéler des routes d’API, d’anciens chemins ou des fonctionnalités côté client.
Pour trouver les fichiers .js :
cat urls.txt | grep ".js"Pour un filtrage un peu plus propre, vous pouvez utiliser :
cat urls.txt | grep -E "\.js($|\?)"Ici, grep -E active les expressions régulières étendues. Pas de panique, une expression régulière est simplement une manière plus précise de rechercher un motif.
La partie \.js cherche vraiment l’extension .js. Le point est précédé d’un antislash, car dans une expression régulière, le point a normalement une signification spéciale. La partie ($|\?) signifie : soit la ligne se termine après .js, soit il y a un ?juste après.
En clair, cette commande cherche des fichiers JavaScript propres, comme :
https://example.com/app.js
https://example.com/script.js?v=2Supprimer les doublons
Les archives peuvent contenir plusieurs fois la même URL. Pour nettoyer les résultats, utilisez sort -u.
cat urls.txt | sort -u > urls-uniques.txtLa commande sort trie les lignes. L’option -u signifie “unique”. Elle supprime donc les doublons.
Vous obtenez un fichier plus propre :
urls-uniques.txtC’est souvent ce fichier que vous utiliserez ensuite pour votre analyse.
Compter le nombre d’URLs trouvées
Pour savoir combien d’URLs vous avez récupérées, utilisez wc -l.
cat urls-uniques.txt | wc -lwc signifie word count, mais avec l’option -l, il compte les lignes. Comme chaque URL est sur une ligne, vous obtenez le nombre total d’URLs.
Exemple :
1248Cela signifie que votre fichier contient 1248 URLs uniques.
Créer un mini workflow simple
Maintenant que vous connaissez les bases, assemblons une petite méthode propre.
echo "example.com" | waybackurls | sort -u > urls-uniques.txtCette commande fait plusieurs choses :
- Elle envoie le domaine à Waybackurls,
- récupère les URLs archivées,
- supprime les doublons,
- puis enregistre le résultat dans un fichier.
C’est une excellente base.

Des formations informatique pour tous !
Débutant ou curieux ? Apprenez le développement web, le référencement, le webmarketing, la bureautique, à maîtriser vos appareils Apple et bien plus encore…
Formateur indépendant, professionnel du web depuis 2006, je vous accompagne pas à pas et en cours particulier, que vous soyez débutant ou que vous souhaitiez progresser. En visio, à votre rythme, et toujours avec pédagogie.
Découvrez mes formations Qui suis-je ?Vous pouvez ensuite extraire les URLs avec paramètres :
cat urls-uniques.txt | grep "?" > urls-parametres.txtPuis les fichiers JavaScript :
cat urls-uniques.txt | grep -E "\.js($|\?)" > fichiers-js.txtEt enfin les fichiers PDF :
cat urls-uniques.txt | grep -E "\.pdf($|\?)" > fichiers-pdf.txtÀ ce stade, vous avez une petite organisation claire :
urls-uniques.txt
urls-parametres.txt
fichiers-js.txt
fichiers-pdf.txtC’est simple, lisible, et beaucoup plus confortable que de tout mélanger dans un seul bloc de texte.
Exemple concret pour un audit SEO
Imaginons que vous ayez refait votre site il y a quelques années. Vous voulez savoir si d’anciennes pages pourraient encore mériter une redirection.
Vous lancez :
echo "votresite.fr" | waybackurls | sort -u > anciennes-urls.txtEnsuite, vous cherchez les anciennes pages HTML ou PHP :
cat anciennes-urls.txt | grep -E "\.html|\.php" > anciennes-pages.txtVous pouvez ouvrir anciennes-pages.txt et repérer les URLs qui ressemblent à de vrais contenus :
https://votresite.fr/ancienne-formation-html.html
https://votresite.fr/blog/referencement-naturel.php
https://votresite.fr/services/creation-site-web.htmlSi ces pages n’existent plus, posez-vous une question simple : existe-t-il aujourd’hui une page équivalente ou proche ?
Si oui, une redirection 301 peut être pertinente. Elle permet d’envoyer les visiteurs et les moteurs de recherche vers la nouvelle page. Cela évite les erreurs 404 et améliore l’expérience utilisateur.
Exemple concret pour un audit de sécurité défensif
Prenons maintenant un cas côté sécurité. Vous analysez votre propre site pour repérer d’anciens chemins sensibles.
Vous pouvez chercher les URLs contenant certains mots :
cat urls-uniques.txt | grep -Ei "admin|login|backup|test|dev|api"- L’option
-Eactive les expressions régulières étendues. - L’option
-iignore la casse, c’est-à-dire qu’elle ne fait pas de différence entre majuscules et minuscules.
Cette commande peut ressortir des URLs comme :
https://example.com/admin-old
https://example.com/test/login.php
https://example.com/backup/site.zip
https://example.com/api/v1/usersAttention : ne partez pas du principe que tout est dangereux. Une URL trouvée dans les archives n’est pas forcément accessible aujourd’hui. Le bon réflexe consiste à vérifier calmement, dans un cadre autorisé, si ces chemins existent encore et s’ils exposent quelque chose qui ne devrait pas être public.
L’objectif n’est pas de jouer au pirate. L’objectif est de faire le ménage chez soi avant que quelqu’un d’autre ne remarque la poussière sous le tapis.
Tester si les URLs répondent encore
Waybackurls retrouve des URLs historiques. Mais vous voudrez parfois savoir lesquelles sont encore accessibles aujourd’hui.
Pour cela, Waybackurls seul ne suffit pas. Vous pouvez combiner son résultat avec d’autres outils, comme curl.
Voici une commande simple pour tester une URL :
curl -I https://example.com/ancienne-pageL’option -I demande uniquement les en-têtes HTTP, sans télécharger toute la page.
Vous pouvez obtenir une réponse comme :
HTTP/2 200Le code 200 signifie que la page répond correctement.
Autre exemple :
HTTP/2 404Le code 404 signifie que la page est introuvable.
Ou encore :
HTTP/2 301Le code 301 indique une redirection permanente.
Pour les débutants, retenez simplement ceci : les codes HTTP sont des réponses du serveur. Ils indiquent si une page existe, si elle est déplacée, si elle est interdite ou si une erreur s’est produite.
👉 Tout savoir sur : Les codes de statut HTTP
Comprendre les limites de Waybackurls
Waybackurls est très pratique, mais il ne faut pas lui demander plus que ce qu’il peut faire.
D’abord, il dépend des données archivées. Si la Wayback Machine n’a jamais vu une URL, Waybackurls ne pourra pas l’inventer. Il ne scanne pas votre site en direct comme un crawler classique. Il interroge une mémoire existante.
Ensuite, certaines URLs peuvent être anciennes, obsolètes ou inutiles. Vous pouvez obtenir des liens vers des fichiers supprimés depuis longtemps, des pages de test qui n’existent plus ou des paramètres sans intérêt.
Enfin, Waybackurls ne vérifie pas automatiquement si les URLs sont encore actives. Il récupère une liste historique. À vous ensuite de filtrer, tester et interpréter.
C’est un peu comme recevoir une vieille carte au trésor. Elle peut contenir des indications précieuses, mais certains chemins ont peut-être disparu, et la taverne du coin est peut-être devenue une boulangerie.
Bonnes pratiques d’utilisation
Utilisez Waybackurls sur vos propres domaines, sur des projets de test ou dans un cadre où vous avez une autorisation claire. Même si l’outil ne fait que récupérer des URLs publiques ou archivées, l’usage que vous faites ensuite des résultats doit rester responsable.
Pensez aussi à documenter vos analyses. Par exemple, créez un dossier par domaine :
mkdir audit-example
cd audit-examplePuis enregistrez vos fichiers proprement :
echo "example.com" | waybackurls | sort -u > 01-urls-uniques.txt
cat 01-urls-uniques.txt | grep "?" > 02-urls-parametres.txt
cat 01-urls-uniques.txt | grep -Ei "admin|login|backup|test|dev|api" > 03-urls-sensibles.txtLes numéros au début des fichiers permettent de garder un ordre logique. Ce n’est pas obligatoire, mais quand vous reviendrez sur votre audit deux semaines plus tard, votre futur vous dira merci.
Créer un petit script Bash
Si vous utilisez souvent Waybackurls, vous pouvez créer un petit script pour automatiser les commandes de base.
Créez un fichier :
nano analyse-wayback.shAjoutez ce contenu :
#!/bin/bash
# On vérifie qu'un domaine a bien été fourni
if [ -z "$1" ]; then
echo "Utilisation : ./analyse-wayback.sh domaine.fr"
exit 1
fi
# On stocke le domaine dans une variable
DOMAINE=$1
# On crée un dossier de sortie
mkdir -p "resultats-$DOMAINE"
# On récupère les URLs archivées et on supprime les doublons
echo "$DOMAINE" | waybackurls | sort -u > "resultats-$DOMAINE/urls-uniques.txt"
# On extrait les URLs avec paramètres
cat "resultats-$DOMAINE/urls-uniques.txt" | grep "?" > "resultats-$DOMAINE/urls-parametres.txt"
# On extrait les fichiers JavaScript
cat "resultats-$DOMAINE/urls-uniques.txt" | grep -E "\.js($|\?)" > "resultats-$DOMAINE/fichiers-js.txt"
# On extrait les chemins potentiellement sensibles
cat "resultats-$DOMAINE/urls-uniques.txt" | grep -Ei "admin|login|backup|test|dev|api" > "resultats-$DOMAINE/urls-a-verifier.txt"
# Message final
echo "Analyse terminée pour $DOMAINE"
echo "Résultats disponibles dans le dossier resultats-$DOMAINE"Rendez le script exécutable grâce à la commande CHMOD :
chmod +x analyse-wayback.shLancez-le :
./analyse-wayback.sh example.comCe script automatise une petite analyse de départ. Il ne remplace pas votre réflexion, mais il vous évite de retaper les mêmes commandes à chaque fois.
Lire les résultats intelligemment
Une erreur fréquente consiste à croire que plus on a d’URLs, meilleure est l’analyse. En réalité, une grande liste non triée peut vite devenir inutilisable.
- Votre objectif n’est pas seulement de collecter. Votre objectif est de comprendre.
Commencez par identifier les grandes familles d’URLs. Voyez-vous beaucoup d’anciennes pages de blog ? Des fichiers PDF ? Des paramètres ? Des endpoints d’API ? Des sous-domaines ? Des fichiers JavaScript ?
Ensuite, classez les priorités.
Pour le SEO, vous regarderez surtout les anciennes pages importantes, les contenus supprimés, les URLs qui semblent avoir été utiles ou les ressources qui pourraient mériter une redirection.
Pour la sécurité défensive, vous observerez davantage les chemins techniques, les fichiers de sauvegarde, les pages de connexion, les environnements de test et les vieux endpoints.
Pour le développement web, vous pouvez utiliser ces résultats pour mieux comprendre l’évolution d’un projet, retrouver une ancienne structure ou préparer une migration.
Waybackurls et WordPress
Sur un site WordPress, Waybackurls peut retrouver de nombreuses URLs intéressantes : anciens articles, fichiers médias, pages d’auteur, catégories, plugins, thèmes ou anciennes structures de permaliens.
Par exemple :
echo "monsite.fr" | waybackurls | grep "wp-content"Cette commande affiche les URLs contenant wp-content, le dossier où WordPress stocke notamment les thèmes, plugins et fichiers envoyés dans la médiathèque.
Vous pouvez aussi chercher les anciens fichiers PDF :
echo "monsite.fr" | waybackurls | grep -E "\.pdf($|\?)"Ou les anciennes pages de connexion :
echo "monsite.fr" | waybackurls | grep -Ei "wp-login|wp-admin"Encore une fois, le but n’est pas de paniquer dès qu’une URL apparaît. WordPress utilise naturellement certains chemins. L’idée est plutôt d’identifier ce qui mérite une vérification : vieux fichiers, extensions abandonnées, documents sensibles publiés par erreur, anciennes pages sans redirection, etc.
Différence entre Waybackurls et un crawler
Un crawler classique visite votre site actuel. Il part d’une page, suit les liens, explore les contenus disponibles aujourd’hui.
Waybackurls, lui, ne visite pas directement votre site de la même façon. Il récupère des URLs archivées dans le passé. C’est donc un outil complémentaire.
- Un crawler répond plutôt à la question : “Quelles pages existent maintenant ?”
- Waybackurls répond plutôt à la question : “Quelles URLs ont existé ou ont été vues dans le passé ?”
Les deux approches sont utiles. Si vous préparez un audit complet, vous pouvez croiser les résultats. Les URLs trouvées par Waybackurls mais absentes du crawl actuel peuvent signaler d’anciennes pages supprimées, des redirections manquantes ou des contenus oubliés.
Petite méthode d’analyse recommandée
Pour utiliser Waybackurls efficacement, vous pouvez suivre une méthode simple.
- Commencez par récupérer toutes les URLs historiques du domaine.
- Ensuite, supprimez les doublons.
- Une fois cette base propre obtenue, créez plusieurs fichiers de travail : URLs avec paramètres, fichiers JavaScript, documents PDF, chemins sensibles, anciennes pages HTML ou PHP.
Puis prenez le temps de lire les résultats.
N’essayez pas de tout corriger en dix minutes. Une analyse utile demande un peu de patience, comme quand on démêle des écouteurs dans une poche. Techniquement, c’est possible. Émotionnellement, il faut respirer.
Enfin, transformez vos observations en actions concrètes : redirections SEO, suppression de fichiers inutiles, protection de chemins sensibles, nettoyage de documents publics, vérification des anciens endpoints ou amélioration de la structure actuelle du site.
Commandes utiles à retenir
Voici quelques commandes pratiques que vous pourrez réutiliser.
Récupérer les URLs archivées :
echo "example.com" | waybackurlsEnregistrer les résultats :
echo "example.com" | waybackurls > urls.txtSupprimer les doublons :
cat urls.txt | sort -u > urls-uniques.txtChercher les URLs avec paramètres :
cat urls-uniques.txt | grep "?"Chercher les fichiers JavaScript :
cat urls-uniques.txt | grep -E "\.js($|\?)"Chercher des chemins sensibles :
cat urls-uniques.txt | grep -Ei "admin|login|backup|test|dev|api"Compter les URLs :
cat urls-uniques.txt | wc -lTester une URL :
curl -I https://example.com/ancienne-pageCes commandes constituent une très bonne boîte à outils de départ. Vous pourrez ensuite les adapter selon vos besoins.
Erreurs fréquentes à éviter
La première erreur consiste à lancer Waybackurls puis à copier-coller les résultats sans les trier. Vous risquez vite de vous retrouver avec des centaines ou des milliers de lignes peu exploitables.
La deuxième erreur est de croire qu’une URL archivée est forcément encore en ligne. Ce n’est pas le cas. Il faut tester les URLs importantes avant de tirer des conclusions.
La troisième erreur est de confondre collecte et audit. Collecter des URLs, c’est seulement la première étape. La vraie valeur vient de l’analyse : que révèlent ces URLs ? Que faut-il corriger ? Quelles pages doivent être redirigées ? Quels fichiers doivent être supprimés ou protégés ?
Enfin, évitez d’utiliser l’outil sur des sites qui ne vous appartiennent pas dans un objectif intrusif. Waybackurls est un outil neutre. Comme souvent en informatique, tout dépend de l’usage que l’on en fait.
Waybackurls permet-il de voir les pages actuellement en ligne ?
Non. Waybackurls récupère les URLs connues par les archives de la Wayback Machine. Certaines pages peuvent encore exister aujourd’hui, tandis que d’autres ont été supprimées ou modifiées depuis longtemps.
Faut-il être développeur pour utiliser Waybackurls ?
Pas du tout. Quelques connaissances de base du terminal suffisent pour lancer les commandes principales. C’est un excellent outil pour découvrir progressivement l’univers des outils CLI.
Pourquoi récupérer d’anciennes URLs d’un site web ?
Les anciennes URLs peuvent aider à retrouver des pages oubliées, identifier des ressources supprimées, améliorer des redirections SEO ou mieux comprendre l’évolution d’un site au fil du temps.
Waybackurls CLI est un petit outil, mais il ouvre une porte passionnante : celle de la mémoire du Web. En quelques commandes, vous pouvez retrouver d’anciennes URLs, explorer l’historique d’un domaine, repérer des contenus oubliés et mieux comprendre l’évolution d’un site.
Pour un débutant, c’est aussi une excellente occasion de progresser avec le terminal. Vous manipulez des commandes simples, vous apprenez à filtrer des résultats, vous découvrez les pipes, les redirections, grep, sort et quelques bases utiles pour vos futurs audits.
Le plus important maintenant, c’est de pratiquer. Choisissez un domaine que vous gérez, lancez une première collecte, créez vos fichiers de tri, puis observez tranquillement les résultats. Vous verrez qu’au fil des essais, votre regard va s’affiner. Les URLs ne seront plus seulement des lignes étranges dans un terminal : elles deviendront des indices, des traces, parfois même de petites histoires techniques laissées par le passé de votre site.
Et dans le développement web, apprendre à lire ces traces, c’est déjà apprendre à mieux construire l’avenir.

Fondateur de l’agence Créa-troyes, affiliée France Num
Intervenant en Freelance.
Contactez-moi