Le monde des paris sportifs attire chaque année des millions de passionnés. Mais derrière l’excitation du jeu se cache une véritable science des probabilités. Aujourd’hui, grâce aux technologies modernes, il est possible de combiner les statistiques sportives avec le machine learning pour améliorer vos prédictions. Dans ce tutoriel, nous allons explorer pas à pas un script PHP conçu pour analyser des matchs de football et prédire leur résultat à l’aide d’un modèle de machine learning.
L’objectif principal de ce script est de fournir un outil capable de traiter les données de matchs passés, d’évaluer la forme des équipes et de générer une prédiction sur l’issue d’un match à venir. Nous aborderons chaque partie du script, ses principes de fonctionnement, ses avantages et ses limites, tout en expliquant de manière simple et détaillée chaque action réalisée.
À la fin de ce tutoriel, vous serez capable de comprendre comment un modèle de machine learning peut être utilisé pour les paris sportifs et quelles précautions prendre pour interpréter correctement les résultats.
Retrouver ce script complet sur Github.
A quoi sert ce script PHP utilisant le Machine Learning ?
Le script que nous allons étudier a une fonction principale : analyser les performances passées des équipes de football et prédire les résultats des matchs à venir. Il se concentre sur les matchs d’une compétition spécifique, ici la Ligue 1, et utilise des statistiques récentes pour évaluer la forme des équipes.
En pratique, il récupère les résultats de plusieurs rencontres, calcule la performance moyenne de chaque équipe sur ses derniers matchs, et utilise ces informations comme base pour entraîner un modèle de machine learning.
L’intérêt pour les amateurs de paris sportifs est évident. Plutôt que de se baser uniquement sur leur intuition ou sur des informations partielles, les utilisateurs peuvent obtenir une prédiction fondée sur des données historiques.
Ce script ne se limite pas à prédire un gagnant, il permet également de déterminer si un pari a un potentiel « value bet », c’est-à-dire un pari où la probabilité estimée du résultat est supérieure à celle suggérée par les cotes proposées par les bookmakers.
Cependant, il est important de rappeler que ce type de script ne garantit jamais un gain. Il fournit une estimation basée sur des données passées et sur un modèle statistique.
Les résultats du football peuvent être influencés par des facteurs imprévisibles tels que les blessures, les décisions arbitrales ou les conditions météorologiques. Ainsi, ce script doit être utilisé comme un outil d’aide à la décision et non comme une méthode infaillible de prédiction.
<?php
require 'vendor/autoload.php';
use Phpml\Classification\KNearestNeighbors;
use Phpml\Metric\Accuracy;
$apiKey = 'API_KEY'; // remplace par ta clé API
$competition = 'FL1'; // Ligue 1
$status = 'FINISHED';
// --- 1. Récupérer les matchs via l'API ---
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://api.football-data.org/v4/competitions/$competition/matches?status=$status");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, ["X-Auth-Token: $apiKey"]);
$response = curl_exec($ch);
curl_close($ch);
$data = json_decode($response, true);
$matches = $data['matches'];
// --- 2. Calculer forme des équipes sur les 5 derniers matchs ---
$teamHistory = [];
foreach ($matches as $match) {
foreach (['homeTeam','awayTeam'] as $type) {
$team = $match[$type]['name'];
$teamHistory[$team][] = $match;
}
}
function calculerForme($team, $teamHistory){
$dernieres = array_slice(array_reverse($teamHistory[$team]),0,5);
$score = 0;
foreach ($dernieres as $m){
$home = $m['homeTeam']['name'];
$away = $m['awayTeam']['name'];
$hg = $m['score']['fullTime']['home'];
$ag = $m['score']['fullTime']['away'];
if($team==$home){
if($hg>$ag) $score+=1;
elseif($hg==$ag) $score+=0.5;
} else {
if($ag>$hg) $score+=1;
elseif($ag==$hg) $score+=0.5;
}
}
return $score/5;
}
// --- 3. Préparer données pour ML ---
$samples = $labels = [];
$matches_data = [];
$team_forms = []; // Ajout pour stocker la forme de chaque équipe
foreach ($matches as $m){
$home_team = $m['homeTeam']['name'];
$away_team = $m['awayTeam']['name'];
$hg = $m['score']['fullTime']['home'];
$ag = $m['score']['fullTime']['away'];
$home_form = calculerForme($home_team,$teamHistory);
$away_form = calculerForme($away_team,$teamHistory);
// Stocker la forme pour une récupération facile plus tard
$team_forms[$home_team] = $home_form;
$team_forms[$away_team] = $away_form;
$samples[] = [$home_form, $away_form];
if ($hg>$ag) $labels[]='Domicile (1)';
elseif ($hg<$ag) $labels[]='Exterieur (2)';
else $labels[]='Nul (N)';
$matches_data[] = [
'home_team'=>$home_team,
'away_team'=>$away_team,
'home_form'=>$home_form,
'away_form'=>$away_form,
'home_odds'=>2.0, // par défaut
'draw_odds'=>3.0,
'away_odds'=>3.5
];
}
// --- 4. Entraîner modèle ---
$classifier = new KNearestNeighbors();
$classifier->train($samples,$labels);
// --- 5. Évaluer précision ---
$predicted = $classifier->predict($samples);
$accuracy = \Phpml\Metric\Accuracy::score($labels,$predicted);
// --- 6. Formulaire ---
$teams = array_unique(array_merge(array_column($matches_data,'home_team'), array_column($matches_data,'away_team')));
sort($teams);
$home_team = $_POST['home_team'] ?? null;
$away_team = $_POST['away_team'] ?? null;
?>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Prédiction Paris Ligue 1</title>
<style>
/* Global */
body {
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Oxygen, Ubuntu, Cantarell, "Fira Sans", "Droid Sans", "Helvetica Neue", sans-serif;
background: linear-gradient(135deg, #f8f8f8, #e0e0e0);
margin: 0;
padding: 0;
color: #1c1c1e;
}
/* Container principal */
.container {
max-width: 650px;
margin: 80px auto;
background: #ffffff;
padding: 40px;
border-radius: 20px;
box-shadow: 0 20px 40px rgba(0, 0, 0, 0.08);
backdrop-filter: blur(10px);
}
/* Titres */
h2 {
text-align: center;
font-weight: 600;
font-size: 2rem;
color: #111;
margin-bottom: 30px;
}
/* Formulaire : équipe vs équipe */
form {
display: flex;
justify-content: center;
align-items: center;
gap: 15px;
margin-bottom: 30px;
}
/* Sélecteurs */
select {
-webkit-appearance: none; /* Supprime le style natif Safari/Chrome */
-moz-appearance: none; /* Supprime style Firefox */
appearance: none; /* Standard */
padding: 15px 40px 15px 15px; /* Espace pour flèche personnalisée */
font-size: 1rem;
border-radius: 12px;
border: 1px solid #d1d1d6;
background: #f2f2f7 url('data:image/svg+xml;utf8,<svg xmlns="http://www.w3.org/2000/svg" width="10" height="10" viewBox="0 0 10 10"><polygon points="0,0 10,0 5,5" fill="%23666"/></svg>') no-repeat right 12px center;
background-size: 12px;
color: #1c1c1e;
transition: all 0.3s ease;
min-width: 200px;
}
select:focus {
outline: none;
border-color: #007aff;
box-shadow: 0 0 0 3px rgba(0, 122, 255, 0.2);
}
/* Ajouter un conteneur pour forcer position relative si nécessaire */
.select-wrapper {
position: relative;
display: inline-block;
width: 200px;
}
/* Petite astuce pour Safari iOS : */
select::-ms-expand {
display: none; /* cache la flèche sur IE/Edge */
}
/* Texte "VS" entre les équipes */
.vs {
font-weight: 700;
font-size: 1.5rem;
color: #007aff;
}
/* Bouton */
button {
padding: 15px 25px;
font-size: 1rem;
border-radius: 12px;
border: none;
background: linear-gradient(135deg, #007aff, #0a84ff);
color: #fff;
cursor: pointer;
transition: all 0.3s ease;
font-weight: 600;
}
button:hover {
background: linear-gradient(135deg, #0a84ff, #007aff);
transform: translateY(-2px);
box-shadow: 0 10px 20px rgba(0, 122, 255, 0.2);
}
/* Résultats */
.result {
text-align: center;
font-size: 1.2rem;
font-weight: 500;
margin-top: 20px;
padding: 15px;
border-radius: 15px;
background: #f2f2f7;
color: #111;
box-shadow: inset 0 0 10px rgba(0,0,0,0.05);
}
/* Précision du modèle */
p {
text-align: center;
font-size: 1rem;
color: #555;
margin-bottom: 30px;
}
</style>
</head>
<body>
<div class="container">
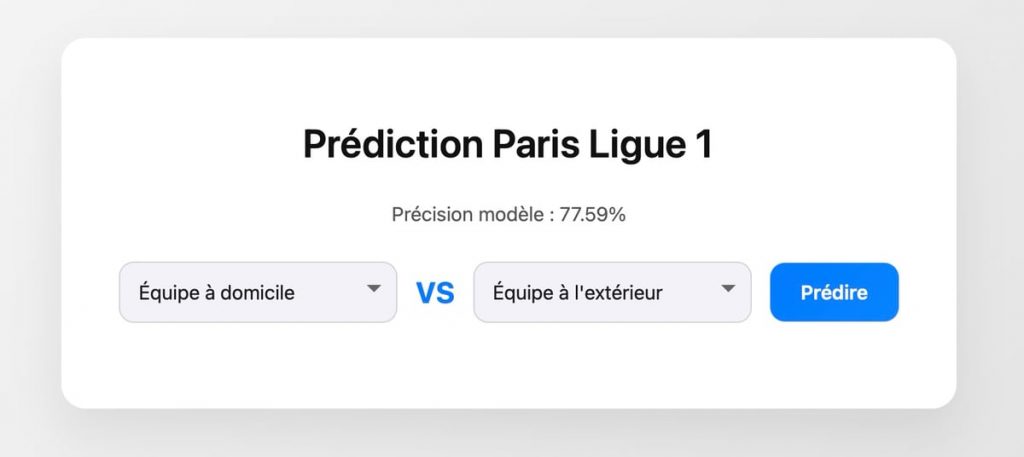
<h2>Prédiction Paris Ligue 1</h2>
<p>Précision modèle : <?php echo round($accuracy * 100, 2); ?>%</p>
<form method="post">
<select name="home_team" required>
<option value="">Équipe à domicile</option>
<?php foreach ($teams as $team): ?>
<option value="<?= $team ?>" <?= ($home_team == $team) ? 'selected' : '' ?>><?= $team ?></option>
<?php endforeach; ?>
</select>
<span class="vs">VS</span>
<select name="away_team" required>
<option value="">Équipe à l'extérieur</option>
<?php foreach ($teams as $team): ?>
<option value="<?= $team ?>" <?= ($away_team == $team) ? 'selected' : '' ?>><?= $team ?></option>
<?php endforeach; ?>
</select>
<button type="submit">Prédire</button>
</form>
<?php
if($home_team && $away_team){
// Récupérer la forme de chaque équipe directement
$home_form = $team_forms[$home_team] ?? 0; // Utilise 0 si l'équipe n'est pas trouvée
$away_form = $team_forms[$away_team] ?? 0;
$sample = [$home_form, $away_form];
$prediction = $classifier->predict([$sample])[0];
echo "<div class='result'>Résultat prédit : <b>$prediction</b></div>";
// Logique de value bet (cotes par défaut pour l'instant)
$odds = ['home_odds'=>2.0, 'draw_odds'=>3.0, 'away_odds'=>3.5];
$value_bet = 'Non'; // Par défaut
if($prediction == 'home_win' && $home_form * $odds['home_odds'] > 1) {
$value_bet = 'Oui';
} elseif ($prediction == 'draw' && 0.5 * $odds['draw_odds'] > 1) { // Une estimation pour le nul
$value_bet = 'Oui';
} elseif ($prediction == 'away_win' && $away_form * $odds['away_odds'] > 1) {
$value_bet = 'Oui';
}
echo "<div class='result'>Value bet détecté ? <b>$value_bet</b></div>";
}
?>
</div>
</body>
</html>Les avantages et limites de ce type de script
L’un des principaux avantages de ce script est sa capacité à traiter rapidement de grandes quantités de données. Avec seulement quelques lignes de code, il peut analyser plusieurs saisons de matchs et calculer la forme des équipes en quelques secondes. Cela offre un gain de temps considérable par rapport à un travail manuel d’analyse statistique.
Un autre avantage est l’utilisation du machine learning. Cette approche permet de détecter des patterns ou des tendances dans les résultats passés, ce qui peut être difficile à identifier à l’œil nu. Le script utilise un modèle simple mais efficace, le K-Nearest Neighbors, qui est particulièrement adapté aux petites bases de données et aux situations où l’on cherche à comparer des performances similaires.
Enfin, le script propose une interface utilisateur conviviale. Il permet de choisir les équipes depuis un formulaire simple et de recevoir immédiatement une prédiction. Cette approche interactive le rend accessible même à ceux qui n’ont pas de connaissances approfondies en programmation ou en statistiques.
Les limites
Malgré ses avantages, ce type de script présente des limites importantes. Tout d’abord, le modèle utilisé ne prend en compte qu’un nombre limité de facteurs : principalement la forme récente des équipes. D’autres éléments cruciaux pour les paris sportifs, comme les absences de joueurs clés, les confrontations directes ou les statistiques avancées, ne sont pas inclus.
Le modèle peut également être influencé par des biais dans les données. Si certaines équipes ont joué moins de matchs ou si les données sont incomplètes, les prédictions peuvent être moins fiables. De plus, le K-Nearest Neighbors, bien qu’efficace pour des petits ensembles de données, peut devenir moins performant lorsque le volume de matchs analysés augmente fortement.
Enfin, il est essentiel de rappeler que le machine learning dans le contexte des paris sportifs ne remplace pas l’intuition et l’analyse humaine. Les prédictions sont des probabilités, pas des certitudes. Il est donc important d’utiliser le script comme un complément à vos propres recherches et décisions de pari.
Les grands principes du script PHP utilisant le machine learning pour la prédiction des résultats de ligue 1
Le script repose sur plusieurs étapes clés que nous allons détailler. Comprendre ces principes est essentiel pour saisir le fonctionnement global et pouvoir adapter ou améliorer le code selon vos besoins.
Récupération des données
La première étape consiste à récupérer les résultats des matchs depuis une source externe. Dans ce cas, le script utilise une API spécialisée pour le football, qui fournit les scores et les informations des rencontres. Les données incluent le nom des équipes, le score final, et d’autres informations utiles. L’intérêt de cette approche est d’automatiser la collecte des données et de garantir qu’elles soient toujours à jour.
Calcul de la forme des équipes
Une fois les données récupérées, le script évalue la forme de chaque équipe sur ses cinq derniers matchs. Pour cela, il analyse les victoires, les défaites et les matchs nuls. Chaque résultat est converti en un score : une victoire vaut 1 point, un match nul 0,5 point, et une défaite 0 point. Ensuite, la moyenne de ces scores sur les cinq derniers matchs est calculée pour obtenir une estimation de la performance actuelle de l’équipe.
Cette étape est cruciale, car elle permet de transformer des résultats bruts en indicateurs numériques exploitables par le modèle de machine learning. La forme d’une équipe est souvent un bon indicateur de sa performance future, ce qui justifie son inclusion dans l’analyse.
Préparation des données pour le machine learning
Après avoir calculé la forme de chaque équipe, la prochaine étape consiste à préparer les données pour le modèle de machine learning. Dans ce script, chaque match est représenté par un ensemble de valeurs numériques appelées features, ici la forme de l’équipe à domicile et la forme de l’équipe à l’extérieur. Ces valeurs sont stockées dans un tableau appelé samples. Chaque match dispose également d’une étiquette (label), correspondant au résultat : victoire de l’équipe à domicile, victoire de l’équipe à l’extérieur ou match nul.
La préparation des données est une étape clé en machine learning. Un modèle ne peut apprendre que si les données sont correctement organisées. Les samples représentent les informations d’entrée que le modèle va analyser, tandis que les labels représentent la sortie que l’on souhaite prédire. Plus les données sont précises et pertinentes, plus le modèle sera capable de faire des prédictions fiables.
Il est important de noter que dans ce script, les cotes des bookmakers sont également intégrées mais restent pour l’instant des valeurs par défaut. Ces cotes peuvent servir dans une étape ultérieure pour calculer le « value bet » ou pour améliorer le modèle en combinant les probabilités implicites et la forme des équipes.
Entraînement du modèle de machine learning
Le script utilise un modèle simple mais efficace, appelé K-Nearest Neighbors (KNN). Ce modèle fait partie des méthodes de machine learning supervisé, ce qui signifie qu’il apprend à partir d’exemples pour prédire un résultat futur. Le principe de KNN est simple : lorsqu’une nouvelle rencontre est soumise au modèle, celui-ci recherche les matchs les plus similaires dans l’historique et prédit le résultat en fonction de la majorité des résultats voisins.
L’avantage du KNN est sa simplicité et sa capacité à fonctionner avec de petits ensembles de données. Il ne nécessite pas de calculs complexes ou d’optimisations lourdes. Cependant, il peut devenir moins performant avec des ensembles de données très volumineux ou déséquilibrés. Pour ce type d’application dans les paris sportifs, où le nombre de matchs disponibles peut être limité, KNN est un choix pertinent.
L’entraînement du modèle consiste donc à fournir au KNN la liste de samples et les labels correspondants. Le modèle va mémoriser ces données et être capable de comparer toute nouvelle rencontre à ces exemples passés pour prédire son issue.

Des formations informatique pour tous !
Débutant ou curieux ? Apprenez le développement web, le référencement, le webmarketing, la bureautique, à maîtriser vos appareils Apple et bien plus encore…
Formateur indépendant, professionnel du web depuis 2006, je vous accompagne pas à pas et en cours particulier, que vous soyez débutant ou que vous souhaitiez progresser. En visio, à votre rythme, et toujours avec pédagogie.
Découvrez mes formations Qui suis-je ?Évaluation de la précision du modèle
Une fois le modèle entraîné, il est important de mesurer sa performance. Dans le script, cette étape est réalisée à l’aide d’une métrique appelée précision (accuracy). La précision correspond au pourcentage de prédictions correctes par rapport aux résultats réels. Pour calculer cette métrique, le script compare les résultats prédits par le modèle aux résultats connus des matchs utilisés pour l’entraînement.
Bien que cette méthode permette d’obtenir une première indication sur la qualité du modèle, elle présente certaines limites. Comme le modèle est évalué sur les mêmes données qui ont servi à son entraînement, la précision peut être surévaluée. Dans un contexte professionnel de machine learning, on utilise généralement des jeux de données distincts pour l’entraînement et pour l’évaluation afin d’éviter ce biais. Néanmoins, pour un script simple destiné aux paris sportifs, cette évaluation offre un aperçu utile de l’efficacité du modèle.
Création d’un formulaire interactif
Pour rendre le script accessible et interactif, une interface web est intégrée. Cette interface permet de sélectionner les équipes à domicile et à l’extérieur à partir d’une liste déroulante. Le formulaire envoie ensuite les données sélectionnées au script pour générer la prédiction.
Cette approche présente plusieurs avantages. Tout d’abord, elle ne nécessite aucune connaissance en programmation pour l’utilisateur final. Ensuite, elle permet de tester rapidement différentes combinaisons d’équipes et de voir instantanément le résultat prédit. Enfin, elle sert de base pour intégrer d’autres fonctionnalités, comme le calcul de « value bet » ou l’ajout de statistiques supplémentaires.
Le design du formulaire et de la page est également soigné pour offrir une expérience agréable, avec des boutons colorés et un affichage clair des résultats. Même si l’aspect visuel n’influence pas directement les prédictions, il est important pour la compréhension et l’accessibilité du script.
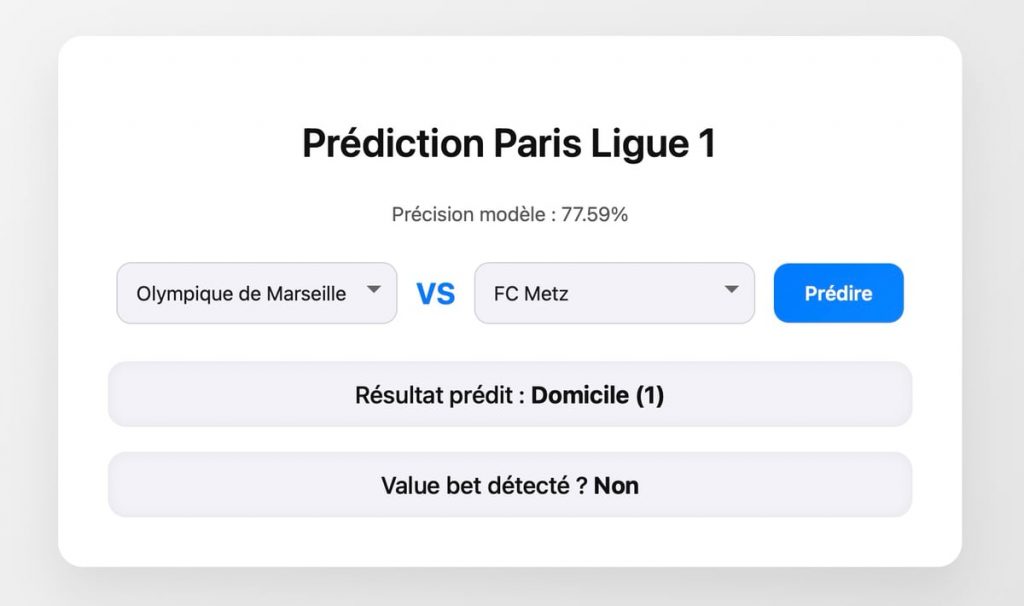
Prédiction et calcul du « value bet »
Une fois les équipes sélectionnées, le script récupère la forme de chaque équipe et crée un nouvel échantillon de données. Ce nouvel échantillon est ensuite soumis au modèle KNN pour générer une prédiction. Le résultat affiché indique si l’équipe à domicile gagne, si l’équipe à l’extérieur gagne, ou si le match se termine par un nul.
Parallèlement, le script propose une évaluation rapide d’un « value bet ». Le concept de value bet repose sur le fait qu’un pari est intéressant si la probabilité estimée du résultat est supérieure à celle suggérée par les cotes des bookmakers. Dans le script, un calcul simple compare la forme de l’équipe et la cote proposée pour déterminer si le pari est potentiellement avantageux. Bien sûr, ce calcul est simplifié et pourrait être amélioré en intégrant des probabilités plus précises et en tenant compte de facteurs supplémentaires.
Optimisation et amélioration du script pour les paris sportifs
Le script que nous avons étudié est fonctionnel, mais il existe plusieurs façons de l’améliorer pour le rendre plus précis et utile dans le cadre des paris sportifs. Comprendre ces améliorations vous permettra non seulement de tirer le meilleur parti de vos prédictions, mais aussi d’apprendre les bonnes pratiques en machine learning appliqué au sport.
Ajouter des données supplémentaires
L’un des points faibles du script actuel est qu’il ne prend en compte que la forme récente des équipes. Bien que cette information soit utile, d’autres facteurs peuvent fortement influencer le résultat d’un match. Par exemple, les absences de joueurs clés, les performances à domicile ou à l’extérieur, les confrontations directes passées, ou encore les statistiques avancées comme le nombre de tirs cadrés ou la possession de balle.
En intégrant ces informations dans les features de votre modèle, vous pouvez améliorer significativement la précision des prédictions. Dans le cas du KNN, chaque nouvelle donnée devient une dimension supplémentaire dans l’espace des caractéristiques, ce qui permet au modèle de mieux comparer les matchs similaires.
Ajuster le modèle KNN
Le KNN utilisé dans le script est initialisé avec les paramètres par défaut. Cependant, la performance de ce type de modèle peut varier selon le nombre de voisins considérés et la méthode de calcul des distances. Par exemple, tester différents nombres de voisins peut influencer la sensibilité du modèle aux variations dans les données. De même, choisir une distance adaptée (euclidienne, manhattan, etc.) peut améliorer la capacité du modèle à identifier des matchs similaires.
Ces ajustements font partie du processus de tuning du modèle en machine learning. L’objectif est de trouver la combinaison de paramètres qui maximise la précision tout en évitant le surapprentissage, c’est-à-dire lorsque le modèle mémorise trop les données et perd sa capacité à généraliser.
Validation croisée
Une pratique essentielle en machine learning est la validation croisée. Dans le script actuel, la précision est mesurée sur les mêmes données utilisées pour entraîner le modèle. Cela peut donner une impression de performance trop optimiste. La validation croisée consiste à diviser les données en plusieurs parties, à entraîner le modèle sur certaines parties et à le tester sur d’autres. Cette méthode permet d’obtenir une estimation plus réaliste de la performance du modèle sur des données non vues.
Pour les paris sportifs, cette étape est particulièrement utile, car elle permet de vérifier que le modèle peut prédire correctement des matchs futurs et non uniquement ceux déjà joués.
Améliorer le calcul du « value bet »
Le calcul du value bet dans le script est simplifié : il compare la forme de l’équipe et la cote proposée pour déterminer si un pari est intéressant. Cependant, dans la pratique, il est possible d’affiner cette approche. Par exemple, vous pouvez convertir la forme et les cotes en probabilités implicites et calculer un ratio entre la probabilité estimée par le modèle et celle proposée par le bookmaker. Si ce ratio est supérieur à 1, le pari est considéré comme un value bet. Cette méthode permet d’intégrer des notions de probabilité et de risque plus précises.
Interface utilisateur et expérience
Un autre aspect à considérer est l’interface utilisateur. Actuellement, le script propose un formulaire simple et clair, mais il est possible de le rendre plus interactif. Par exemple, vous pouvez ajouter des graphiques pour visualiser la forme des équipes, un historique des résultats récents, ou encore une explication des prédictions générées par le modèle. Ces éléments permettent à l’utilisateur de mieux comprendre la logique derrière chaque prédiction et d’interpréter les résultats avec plus de confiance.
Limites à garder à l’esprit
Même après optimisation, il est essentiel de rappeler que le machine learning appliqué aux paris sportifs présente des limites. Les prédictions restent des probabilités, pas des certitudes. Les facteurs imprévus, comme les blessures de dernière minute ou les décisions arbitrales, peuvent toujours modifier le résultat d’un match.
De plus, un modèle basé sur les performances passées peut être biaisé si certaines équipes ont joué moins de matchs ou si des données sont manquantes. Il est donc conseillé de toujours combiner les résultats du script avec votre analyse personnelle et de ne jamais parier plus que ce que vous êtes prêt à perdre.
Bonnes pratiques pour utiliser ce script
Pour tirer le meilleur parti de ce type d’outil, il est recommandé de suivre plusieurs bonnes pratiques. Tout d’abord, actualisez régulièrement les données pour que le modèle soit toujours entraîné sur des informations récentes. Ensuite, testez différentes configurations du modèle et comparez les résultats afin de trouver celle qui offre la meilleure précision.
Enfin, utilisez les prédictions comme un guide plutôt que comme une vérité absolue. Combinez les résultats avec d’autres indicateurs, comme les cotes des bookmakers, les performances individuelles des joueurs et les analyses tactiques. Cette approche combinée augmente vos chances de prendre des décisions éclairées dans le cadre des paris sportifs.
Ce tutoriel vous a permis de comprendre en détail le fonctionnement d’un script PHP dédié aux paris sportifs utilisant le machine learning. Nous avons exploré la récupération des données via une API, le calcul de la forme des équipes, la préparation des données pour le modèle KNN, l’entraînement et l’évaluation de la précision, ainsi que l’interface utilisateur permettant d’obtenir des prédictions.
Au-delà des aspects techniques, ce script illustre parfaitement comment le machine learning peut être appliqué aux paris sportifs pour transformer des données brutes en prédictions exploitables. Il permet de prendre des décisions plus informées, d’identifier des opportunités de value bet, et d’automatiser l’analyse de nombreux matchs.
Cependant, il est crucial de rappeler que ces outils ne remplacent jamais l’analyse humaine et ne garantissent pas de gains. Le machine learning dans les paris sportifs reste un complément puissant à votre intuition et à votre connaissance du sport. En combinant les techniques présentées dans ce tutoriel avec une approche réfléchie, vous pourrez optimiser vos stratégies de pari tout en vous amusant et en approfondissant vos connaissances en machine learning.
Retrouver ce script complet sur Github.
Chapitre 11 : Machine Learning vs I.A →

Fondateur de l’agence Créa-troyes, affiliée France Num
Intervenant en Freelance.
Contactez-moi