Les en-têtes HTTP sont présents dans chaque échange entre votre navigateur et un serveur web, mais restent invisibles pour la plupart des utilisateurs. Ils contiennent des informations essentielles sur une page, une API ou un fichier, et permettent de comprendre comment fonctionnent le cache, les cookies, les redirections, la sécurité ou encore le type de contenu envoyé.
Dans ce tutoriel, vous allez apprendre à récupérer et analyser les en-têtes HTTP avec des outils simples comme votre navigateur, curl ou PHP. Pas à pas, vous découvrirez comment interpréter les principaux en-têtes afin de mieux déboguer vos applications, optimiser les performances de vos sites web et renforcer leur sécurité, même si vous débutez en développement.
- Comprendre le rôle des en-têtes HTTP et leur impact sur les performances, la sécurité et le fonctionnement d’un site web.
- Apprendre à récupérer facilement les en-têtes HTTP avec votre navigateur, le terminal ou PHP pour analyser une application.
- Développer les bons réflexes pour identifier rapidement les informations importantes et mieux diagnostiquer les problèmes d’un site ou d’une API.
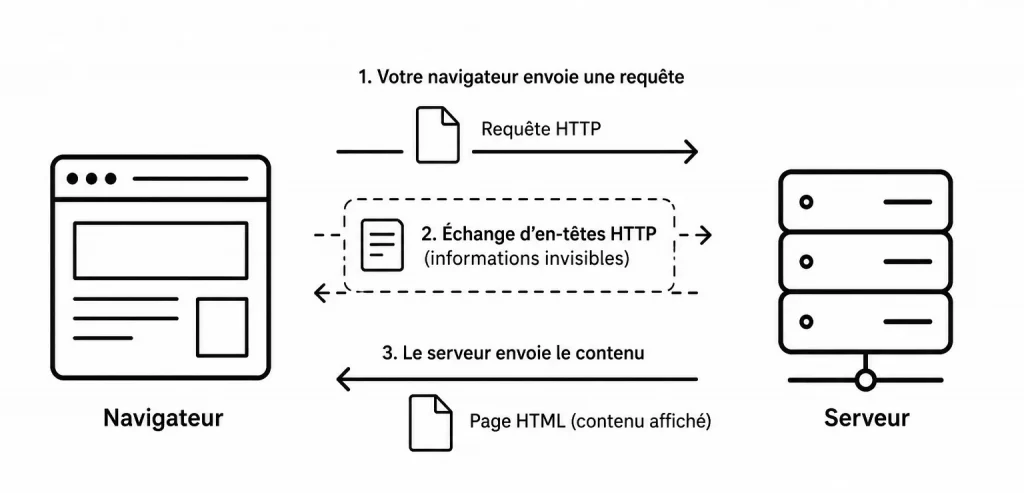
Lorsque vous ouvrez une page web, votre navigateur ne récupère pas uniquement le code HTML. Avant même d’afficher le contenu, il échange de nombreuses informations avec le serveur. Ces informations, invisibles pour la plupart des internautes, sont appelées les en-têtes HTTP (HTTP Headers).
- Qu'est-ce qu'un en-tête HTTP ?
- Les deux familles d'en-têtes HTTP
- Pourquoi les en-têtes HTTP sont-ils si importants ?
- Pourquoi un développeur doit-il apprendre à les lire ?
- Comment récupérer les en-têtes HTTP facilement
- Les Request Headers
- Les Response Headers
- Utiliser la commande cURL
- Récupérer les en-têtes en PHP
- Peut-on récupérer les en-têtes en JavaScript ?
- Utiliser des sites d'analyse HTTP
- Analyser les principaux en-têtes HTTP
- Cas pratiques : apprendre à lire les en-têtes HTTP
- Comment analyser rapidement une réponse HTTP ?
- Les en-têtes HTTP et le SEO
Qu’est-ce qu’un en-tête HTTP ?
Avant de parler d’analyse, il faut comprendre ce qu’est réellement un en-tête HTTP.
Lorsque votre navigateur demande une page web, il envoie une requête au serveur. Le serveur répond ensuite avec la page demandée.
On pourrait imaginer une conversation entre deux personnes.
Le navigateur dit :
Bonjour, je voudrais la page d’accueil.
Le serveur répond :
Très bien. Voici la page. Au passage, elle est en HTML, elle peut être mise en cache pendant une heure, la connexion est sécurisée et je vous donne également un cookie pour vous reconnaître lors de votre prochaine visite.
- Toutes ces informations supplémentaires constituent les en-têtes HTTP.
Ils accompagnent les données mais ne font pas partie de la page HTML elle-même.
Autrement dit :
- les en-têtes décrivent le contenu ;
- le corps (Body) contient le contenu.
C’est exactement comme un colis.
L’étiquette collée sur le carton indique :
- le destinataire,
- l’expéditeur,
- le poids,
- le mode de transport.
À l’intérieur du colis se trouve le véritable contenu.
Les en-têtes HTTP jouent exactement le rôle de cette étiquette.
HTTP : un protocole qui fait dialoguer le Web
Pour bien comprendre les en-têtes, il faut rapidement parler du protocole HTTP.
HTTP signifie : HyperText Transfer Protocol
C’est le langage utilisé pour faire communiquer :
- un navigateur,
- une application mobile,
- un script,
- une API,
- un serveur web.
À chaque clic sur un lien, une nouvelle requête HTTP est envoyée.
- Chaque chargement d’image.
- Chaque fichier CSS.
- Chaque fichier JavaScript.
- Chaque vidéo.
- Chaque police d’écriture.
- Chaque appel AJAX.
Tout passe par HTTP.
Autrement dit, une simple page web peut générer plusieurs dizaines, voire plusieurs centaines de requêtes HTTP.
Et chacune possède ses propres en-têtes.
Les deux familles d’en-têtes HTTP
Les en-têtes se divisent en deux grandes catégories.
Les en-têtes de requête
Ils sont envoyés par le navigateur et permettent d’expliquer au serveur ce que souhaite le client.
Par exemple :
GET / HTTP/1.1
Host: blog.crea-troyes.fr
User-Agent: Mozilla/5.0
Accept: text/html
Accept-Language: frLe navigateur indique notamment :
- quel site il souhaite visiter
- quel navigateur est utilisé
- quelles langues sont acceptées
- quels types de fichiers il peut recevoir
Le serveur peut ainsi adapter sa réponse.
Les en-têtes de réponse
Le serveur répond ensuite :
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 15230
Cache-Control: max-age=3600Le serveur informe ici le navigateur :
- le document est du HTML
- il contient 15 230 octets
- il peut être conservé en cache pendant une heure
Puis seulement après ces informations arrive le contenu HTML.
Visualiser un échange HTTP
Imaginons que vous visitiez la page suivante : https://monsite.fr
Le navigateur envoie :
Bonjour serveur !
Je voudrais la page d'accueil.
Je comprends le HTML.
Je préfère le français.
Voici mon navigateur.Le serveur répond :
Très bien.
La page existe.
Elle est en HTML.
Elle fait 20 Ko.
Vous pouvez la conserver une heure.
La connexion est sécurisée.
Voici un cookie.
Et maintenant... voici la page HTML.Sans ces informations, le navigateur ne saurait pas quoi faire du contenu reçu.
Pourquoi les en-têtes HTTP sont-ils si importants ?
Beaucoup de débutants pensent que seuls le HTML, le CSS et le JavaScript comptent. En réalité, les en-têtes HTTP pilotent une grande partie du fonctionnement du Web.
Ils permettent notamment de gérer :
- la sécurité
- le cache
- les cookies
- la compression
- le type des fichiers
- les redirections
- les téléchargements
- l’authentification
- les API.
Autrement dit, ils influencent directement les performances, le référencement et la sécurité d’un site.
Exemple concret
Imaginez que le serveur envoie une image JPEG. Comment le navigateur sait-il qu’il s’agit d’une image ?
Grâce à cet en-tête :
Content-Type: image/jpegS’il reçoit :
Content-Type: text/htmlIl interprète alors le contenu comme une page web. Un en-tête change donc totalement la façon dont le navigateur traite le fichier.
Les en-têtes sont présents partout
Prenons une page web relativement simple.
Elle contient :
- un fichier HTML
- un fichier CSS
- deux fichiers JavaScript
- cinq images
- une police Google Fonts
Cela représente déjà une dizaine de requêtes HTTP.
Chacune possède :
- ses en-têtes de requête
- ses en-têtes de réponse
- Une seule page peut donc générer plusieurs centaines d’en-têtes HTTP.
Les en-têtes ne sont pas réservés aux sites web
C’est une erreur très fréquente.
- HTTP est utilisé par énormément d’applications.
Par exemple :
- les API REST
- les applications mobiles
- les objets connectés
- les logiciels de bureau
- les assistants vocaux
- certains jeux vidéo
Chaque fois qu’un programme communique via HTTP, il échange également des en-têtes.
Pourquoi un développeur doit-il apprendre à les lire ?
Au début, ils peuvent sembler très techniques. Pourtant, ils permettent de résoudre énormément de problèmes :
- Pourquoi mon fichier CSS ne se charge-t-il pas ?
- Pourquoi mon navigateur utilise-t-il une ancienne version de mon fichier ?
- Pourquoi ma connexion n’est-elle pas sécurisée ?
- Pourquoi mon cookie disparaît-il ?
- Pourquoi mon API refuse ma requête ?
- Pourquoi Google ne met-il pas à jour ma page ?
La réponse se trouve très souvent dans les en-têtes HTTP.
Avec un peu d’habitude, ils deviennent une véritable mine d’informations.
Les en-têtes sont également précieux pour la cybersécurité
Les spécialistes de la sécurité commencent presque toujours par observer les en-têtes HTTP parce qu’ils révèlent énormément d’informations :
- le type de serveur utilisé
- certaines protections activées
- les politiques de sécurité
- la gestion des cookies
- les règles CORS
- la présence de HSTS
- la politique CSP
À l’inverse, certains en-têtes peuvent révéler une mauvaise configuration.
Server: Apache/2.4.7 UbuntuCette information paraît anodine.
Pourtant, elle indique :
- le serveur utilisé
- sa version
- parfois même le système d’exploitation
Un attaquant dispose alors d’informations supplémentaires pour préparer ses recherches. C’est pourquoi beaucoup d’administrateurs choisissent de masquer certains en-têtes.
👉 Apprenez à Sécuriser les Header HTTP en PHP
Les en-têtes évoluent constamment
Le Web change en permanence et de nouveaux en-têtes apparaissent régulièrement. D’autres deviennent obsolètes. Certains sont spécifiques à la sécurité. D’autres concernent uniquement les API modernes.
Il est donc impossible de tous les connaître par cœur.
La bonne approche consiste plutôt à comprendre leur logique.
Une fois que vous aurez compris le rôle général d’un en-tête, il deviendra beaucoup plus simple d’en découvrir de nouveaux au fil de vos projets.
Maintenant que vous comprenez ce que sont les en-têtes HTTP, il est temps de passer à la pratique. Nous allons apprendre à les récupérer facilement avec différents outils accessibles aux débutants.
Comment récupérer les en-têtes HTTP facilement
Maintenant que vous savez ce que sont les en-têtes HTTP, il est temps de passer à la pratique.
La bonne nouvelle, c’est qu’il n’est pas nécessaire d’être un expert en cybersécurité ou un administrateur système pour les consulter. Les navigateurs modernes, le terminal et quelques lignes de code suffisent largement pour les afficher.
Nous allons découvrir plusieurs méthodes, de la plus simple à la plus avancée. Vous pourrez ainsi choisir celle qui correspond le mieux à votre niveau ou à vos habitudes de travail.
Observer les en-têtes directement dans le navigateur
La méthode la plus simple consiste à utiliser les outils de développement intégrés à votre navigateur. Que vous utilisiez Chrome, Firefox, Edge ou Brave, le principe est quasiment identique.
Commencez par ouvrir un site web.
Par exemple : https://blog.crea-troyes.fr
Ensuite, appuyez sur la touche F12. Vous pouvez également faire un clic droit sur la page puis choisir Inspecter.
Une nouvelle fenêtre apparaît. C’est la boîte à outils des développeurs.
Ne vous laissez pas impressionner si vous voyez beaucoup d’informations. Nous allons uniquement nous intéresser à un onglet.
Ouvrir l’onglet Réseau (Network)
Cliquez sur l’onglet Network ou Réseau selon la langue de votre navigateur.
- Cet onglet affiche toutes les communications entre votre navigateur et le serveur.
Si la liste est vide, actualisez simplement la page avec la touche F5. Vous allez alors voir apparaître de nombreuses lignes.
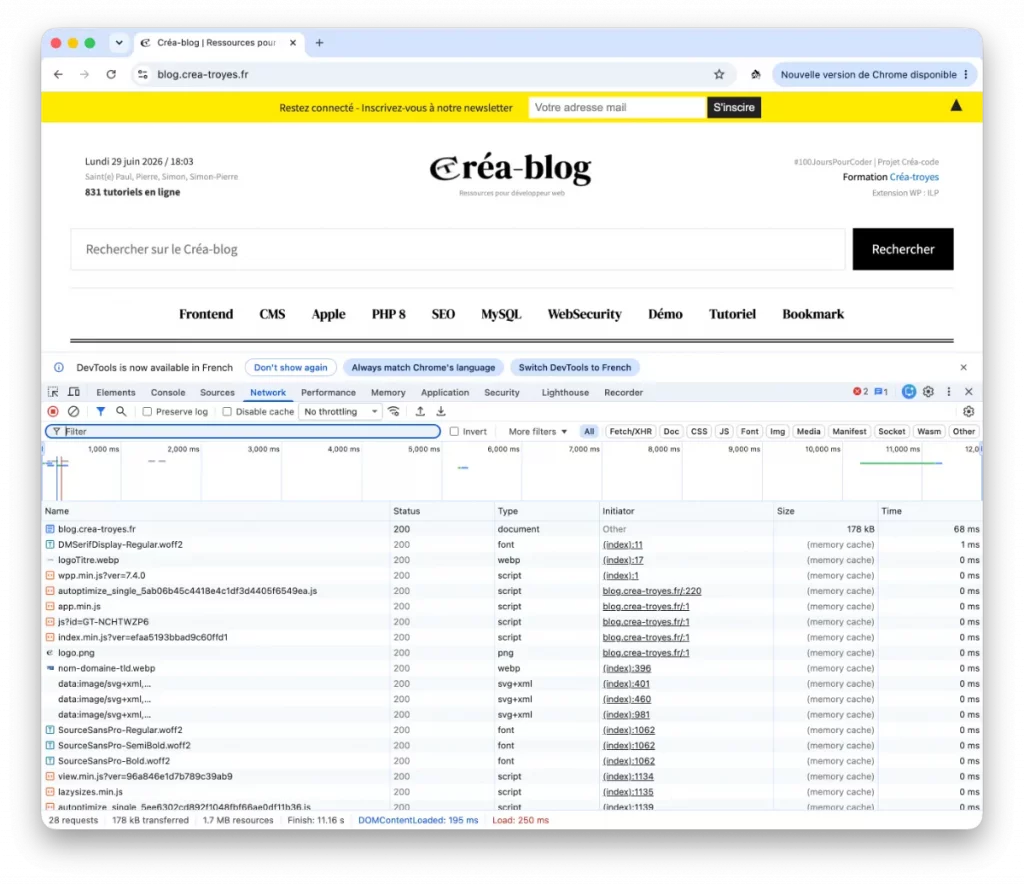
Chaque ligne représente une requête HTTP.
Sélectionner une requête
Cliquez sur la première ligne correspondant à la page HTML. Une nouvelle fenêtre s’ouvre avec plusieurs onglets. L’onglet qui nous intéresse est Headers :
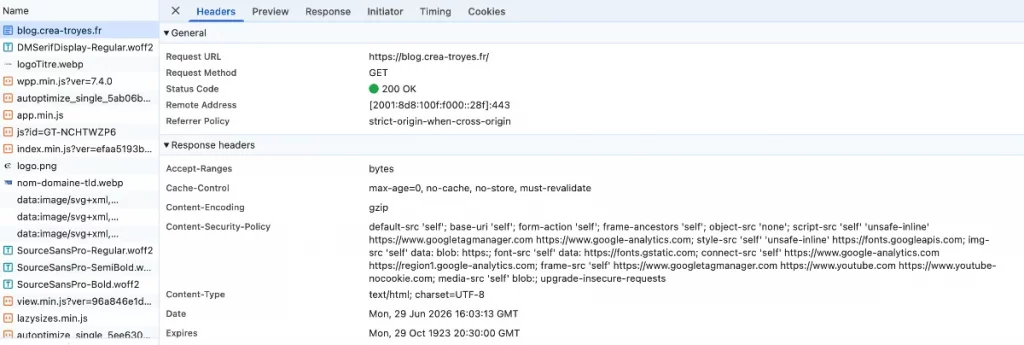
Vous y trouverez les deux grandes familles d’en-têtes.
Les Request Headers
La première partie contient les informations envoyées par votre navigateur. Comme par exemple :
GET / HTTP/2
Host: blog.crea-troyes.fr
User-Agent: Mozilla/5.0
Accept: text/html
Accept-Language: frPrenons le temps de comprendre chacune de ces lignes.
Host
Host: blog.crea-troyes.frLe navigateur indique simplement le site qu’il souhaite consulter.
Cela peut sembler évident, mais un même serveur peut héberger plusieurs dizaines de sites différents. Le serveur a donc besoin de savoir lequel doit répondre.
User-Agent
User-Agent: Mozilla/5.0 ...Cet en-tête décrit le navigateur.
Il permet notamment de connaître :
- le navigateur utilisé
- parfois le système d’exploitation
- parfois l’architecture du processeur
Autrefois, certains sites adaptaient leur affichage en fonction du navigateur détecté. Aujourd’hui, cette pratique est beaucoup moins courante, mais cet en-tête reste très utilisé.
Accept
Accept: text/htmlLe navigateur indique qu’il accepte de recevoir du HTML.
Selon les situations, il peut également accepter :
image/png
image/jpeg
application/json
application/xmlLe serveur adapte alors sa réponse.
Accept-Language
Accept-Language: frLe navigateur précise les langues préférées de l’utilisateur.
C’est grâce à cet en-tête que certains sites affichent automatiquement leur version française.
Les Response Headers
Juste en dessous apparaissent les informations renvoyées par le serveur.
Par exemple :
HTTP/2 200 OK
Content-Type: text/html
Content-Length: 21563
Cache-Control: max-age=3600Ces informations décrivent précisément la réponse.
Nous les analyserons en détail dans la prochaine partie de ce tutoriel.
Utiliser la commande cURL
Les développeurs adorent le terminal parce qu’il permet d’obtenir très rapidement des informations sans ouvrir un navigateur.
- L’outil le plus connu est cURL.
Il est installé par défaut sur macOS et sur la majorité des distributions Linux. Il existe également pour Windows.
👉 Tout savoir sur la commande cURL depuis le terminal.
Vérifier que cURL est installé
Ouvrez votre terminal et tapez simplement :
curl --versionSi cURL est installé, vous verrez apparaître sa version.
Par exemple :
curl 8.7.1Afficher uniquement les en-têtes
Pour récupérer uniquement les en-têtes d’une page, utilisez l’option -I (majuscule).
curl -I https://blog.crea-troyes.frLe résultat ressemble à ceci :
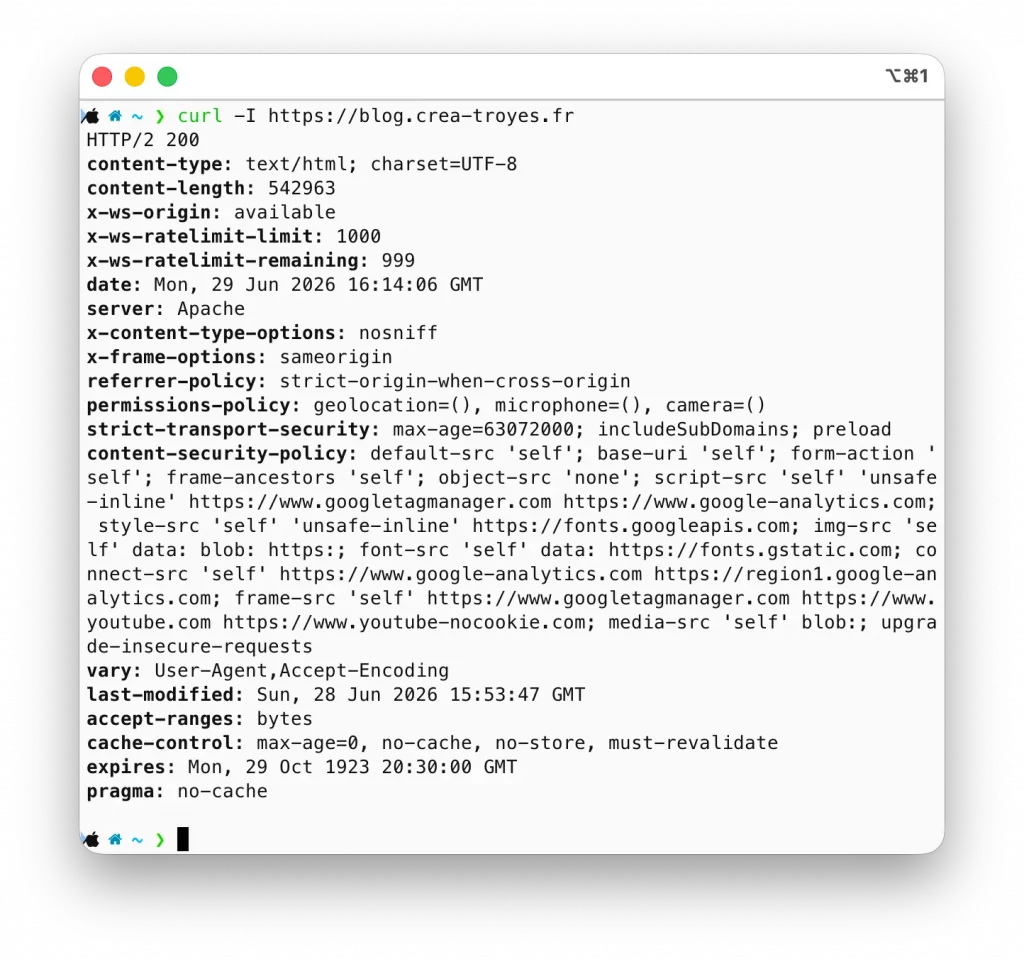
Cette commande est extrêmement pratique.
En une seule ligne, vous obtenez les principales informations de la réponse du serveur.
Pourquoi utiliser l’option -I ?
Sans cette option, cURL télécharge toute la page HTML.
curl https://blog.crea-troyes.frVous verriez alors tout le code HTML défiler dans votre terminal. Ce n’est pas très pratique lorsque l’on souhaite uniquement consulter les en-têtes.
Suivre les redirections
Beaucoup de sites redirigent automatiquement leurs visiteurs.
Par exemple :
http://monsite.frdevient
https://monsite.frPour suivre automatiquement ces redirections, ajoutez l’option :
-LExemple :
curl -IL https://monsite.frVous verrez alors toutes les réponses intermédiaires.
C’est très utile pour comprendre les redirections 301 ou 302.
Afficher les en-têtes et le contenu
Il est également possible d’obtenir les deux.
curl -i https://blog.crea-troyes.frLa différence est subtile.
- -I affiche uniquement les en-têtes.
- -i affiche les en-têtes puis le contenu HTML.
Cette distinction est souvent source de confusion chez les débutants.
Utiliser cURL pour une API
Les API communiquent également via HTTP.
Prenons un exemple simple :
curl https://jsonplaceholder.typicode.com/posts/1Le résultat est du JSON.
Si vous ajoutez :
curl -i https://jsonplaceholder.typicode.com/posts/1Vous verrez :
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: ...Puis le document JSON.
Vous comprenez maintenant que les en-têtes accompagnent absolument tous les échanges HTTP, et pas seulement les pages web.
Récupérer les en-têtes en PHP
En PHP, plusieurs fonctions permettent d’obtenir les en-têtes d’un site distant.
La plus simple est :
<?php
$headers = get_headers("https://blog.crea-troyes.fr");
print_r($headers);Décortiquons ce code.
La fonction get_headers() envoie une requête HTTP. Elle récupère uniquement les en-têtes de réponse.
Le résultat est placé dans un tableau.
Par exemple :
Array
(
[0] => HTTP/2 200
[1] => content-type: text/html
[2] => cache-control: max-age=3600
[3] => server: nginx
)Chaque ligne correspond à un en-tête.
Parcourir les en-têtes
Il est souvent plus pratique de les afficher un par un.
<?php
$headers = get_headers("https://blog.crea-troyes.fr");
foreach($headers as $header)
{
echo $header . "<br>";
}Cette boucle parcourt chaque élément du tableau.
Vous obtenez ainsi une liste claire et facile à lire.
Lire les en-têtes de la requête reçue en PHP
PHP peut également afficher les en-têtes envoyés par le navigateur vers votre serveur.
Sous Apache, on utilise généralement :
<?php
$headers = getallheaders();
echo "<pre>";
print_r($headers);
echo "</pre>";Le résultat peut ressembler à ceci :
Host
Accept
User-Agent
Accept-Language
Cookie
Referer
...C’est particulièrement utile lorsque vous développez une API ou un système d’authentification.
Peut-on récupérer les en-têtes en JavaScript ?
La réponse est :
Oui… mais avec quelques limites.
En JavaScript, lorsqu’on effectue une requête avec fetch(), il est possible de consulter les en-têtes de la réponse.
Voici un exemple.
fetch("https://jsonplaceholder.typicode.com/posts/1")
.then(response => {
console.log(response.headers);
});Cependant, les navigateurs appliquent des règles de sécurité très strictes. Vous ne pourrez pas lire tous les en-têtes.
Le serveur doit explicitement autoriser leur consultation grâce à la politique CORS (Cross-Origin Resource Sharing).
Nous reviendrons sur cette notion un peu plus loin dans l’article.
Afficher un en-tête précis
On peut récupérer un en-tête particulier :
fetch("https://jsonplaceholder.typicode.com/posts/1")
.then(response => {
console.log(
response.headers.get("Content-Type")
);
});Le résultat sera : application/json
Cette méthode est très utilisée dans les applications web modernes.
Utiliser des sites d’analyse HTTP
Si vous ne souhaitez installer aucun outil, plusieurs services en ligne permettent d’inspecter les en-têtes HTTP d’un site.
Il suffit généralement de saisir une adresse web pour obtenir une analyse complète des en-têtes de réponse, des redirections, de la compression, des politiques de sécurité ou encore du cache.
Ces outils sont particulièrement utiles lorsque vous souhaitez réaliser un diagnostic rapide depuis n’importe quel ordinateur, sans passer par le terminal ou les outils de développement du navigateur.
Gardez toutefois à l’esprit que les résultats affichés reflètent ce que ces services observent depuis leurs propres serveurs. Dans certains cas, ils peuvent donc différer légèrement de ce que vous obtenez depuis votre navigateur, notamment si le site adapte son comportement selon la localisation géographique ou certains paramètres de la requête.
Quelle méthode choisir ?
Il n’existe pas de meilleure méthode universelle. Tout dépend de votre objectif.
Si vous souhaitez simplement découvrir les en-têtes d’une page, les outils de développement du navigateur sont idéaux. Ils offrent une interface graphique claire et permettent de visualiser l’ensemble des échanges entre le navigateur et le serveur.
Si vous travaillez régulièrement en ligne de commande ou que vous automatisez certaines tâches, curl deviendra rapidement votre meilleur allié. Il est rapide, disponible sur la plupart des systèmes d’exploitation et très puissant.
Enfin, si vous développez des applications web en PHP ou en JavaScript, récupérer les en-têtes directement dans votre code vous permettra de créer des fonctionnalités avancées, comme la gestion des API, l’authentification ou le contrôle du cache.
Vous savez désormais comment récupérer les en-têtes HTTP. Dans la prochaine partie, nous allons passer à l’étape la plus intéressante : apprendre à analyser les principaux en-têtes, comprendre leur rôle et découvrir comment ils influencent les performances, le référencement naturel (SEO) et la sécurité d’un site web.
Analyser les principaux en-têtes HTTP
Vous savez maintenant comment récupérer les en-têtes HTTP. C’est une excellente première étape, mais elle ne suffit pas. Une liste d’en-têtes ne sert à rien si l’on ne comprend pas ce qu’elle signifie.
C’est un peu comme regarder le tableau de bord d’une voiture sans connaître la signification des voyants. On voit des informations, mais on ne sait pas lesquelles sont importantes.
Dans ce chapitre, nous allons analyser les en-têtes HTTP les plus courants. Vous allez découvrir à quoi ils servent, pourquoi ils existent et comment les interpréter.
Vous n’avez pas besoin de tous les mémoriser. L’objectif est avant tout de comprendre leur rôle.
Le code de réponse HTTP
Avant même les en-têtes, la première ligne de la réponse mérite toute votre attention.

Des formations informatique pour tous !
Débutant ou curieux ? Apprenez le développement web, le référencement, le webmarketing, la bureautique, à maîtriser vos appareils Apple et bien plus encore…
Formateur indépendant, professionnel du web depuis 2006, je vous accompagne pas à pas et en cours particulier, que vous soyez débutant ou que vous souhaitiez progresser. En visio, à votre rythme, et toujours avec pédagogie.
Découvrez mes formations Qui suis-je ?HTTP/2 200 OKCette ligne contient trois informations.
- La version du protocole HTTP utilisée.
- Le code de réponse.
- Une courte description.
Le code est particulièrement important, car il indique immédiatement si la requête s’est bien déroulée.
Voici les principaux codes que vous rencontrerez.
200 OK
HTTP/2 200 OKTout s’est bien passé. Le serveur a trouvé la ressource et l’a envoyée correctement. C’est le code que vous verrez le plus souvent.
301 Moved Permanently
HTTP/2 301 Moved PermanentlyLa page a changé d’adresse de façon permanente. Le navigateur est automatiquement redirigé.
Les moteurs de recherche prennent également en compte cette information pour mettre à jour leur index.
302 Found
HTTP/2 302 FoundLa redirection est temporaire. Contrairement à une redirection 301, le moteur de recherche considère que la page d’origine reviendra probablement.
404 Not Found
HTTP/2 404 Not FoundLe serveur n’a pas trouvé la ressource demandée.
Cela peut être :
- une page supprimée
- une faute de frappe dans l’URL
- un fichier inexistant.
500 Internal Server Error
HTTP/2 500 Internal Server ErrorCette fois, le problème vient du serveur.
Le navigateur a bien envoyé sa demande, mais le serveur a rencontré une erreur avant de pouvoir répondre.
👉 Tout savoir sur Les codes de statut HTTP
Content-Type
C’est probablement l’en-tête le plus connu : Il indique le type du document envoyé.
Content-Type: text/htmlLe navigateur comprend immédiatement qu’il s’agit d’une page HTML.
Voici d’autres exemples.
Content-Type: text/cssLe contenu est une feuille de style CSS.
Content-Type: application/javascriptLe serveur envoie du JavaScript.
Content-Type: image/pngLe fichier est une image PNG.
Content-Type: application/jsonLe contenu est du JSON.
Les API utilisent très souvent cette valeur. Sans cet en-tête, le navigateur ne saurait pas comment interpréter le contenu reçu.
Content-Length
Prenons cet exemple.
Content-Length: 15284Cette valeur indique le nombre d’octets envoyés.
Autrement dit, la taille du document. Cela permet notamment au navigateur de savoir quand le téléchargement est terminé.
Cache-Control
Le cache est un mécanisme essentiel pour accélérer le chargement des sites web. Grâce à lui, le navigateur peut conserver certains fichiers au lieu de les télécharger à chaque visite.
L’en-tête ressemble souvent à ceci.
Cache-Control: max-age=3600Le paramètre max-age=3600 signifie que le fichier peut être conservé pendant 3 600 secondes. Soit une heure.
Durant cette période, le navigateur peut réutiliser le fichier sans contacter le serveur. Ainsi, les pages se chargent beaucoup plus rapidement.
À l’inverse, on rencontre parfois :
Cache-Control: no-cacheou
Cache-Control: no-storeCes valeurs empêchent ou limitent fortement la mise en cache.
Elles sont utiles pour les pages sensibles comme :
- les espaces clients
- les applications bancaires
- les interfaces d’administration
👉 Pour en savoir plus, découvrez les différences entre Cache serveur et cache navigateur
Expires
Avant l’arrivée de Cache-Control, un autre en-tête était très utilisé.
Expires: Wed, 01 Jul 2026 12:00:00 GMTIl indique une date précise d’expiration.
Aujourd’hui, Cache-Control est généralement privilégié, mais vous rencontrerez encore souvent Expires.
Date
Cet en-tête est très simple.
Date: Mon, 29 Jun 2026 15:20:42 GMTIl indique la date à laquelle le serveur a généré la réponse. Cette information peut être utile pour le débogage ou l’analyse du cache.
Server
Cet en-tête indique parfois quel logiciel fait fonctionner le serveur.
Server: nginxou
Server: ApacheParfois même :
Server: Apache/2.4.58Ou encore :
Server: LiteSpeedCela peut être intéressant pour les développeurs.
En revanche, du point de vue de la cybersécurité, afficher la version exacte du serveur n’est généralement pas recommandé. Plus un attaquant possède d’informations sur votre infrastructure, plus il lui est facile de rechercher d’éventuelles vulnérabilités.
C’est pourquoi de nombreux administrateurs choisissent de masquer ou de simplifier cet en-tête.
Set-Cookie
Les cookies sont partout sur Internet. Lorsqu’un serveur souhaite enregistrer un cookie dans votre navigateur, il utilise cet en-tête :
Set-Cookie: session=abc123Le navigateur enregistre alors cette information. Lors de la prochaine visite, il renverra automatiquement ce cookie au serveur.
C’est ce mécanisme qui permet notamment :
- de rester connecté à un site
- de mémoriser votre panier d’achat
- de conserver certaines préférences
Cookie
Cette fois, le rôle est inversé : Le navigateur renvoie les cookies enregistrés.
Cookie: session=abc123Le serveur reconnaît immédiatement le visiteur.
Il peut ainsi retrouver sa session.
Location
Vous rencontrerez souvent cet en-tête après une redirection :
HTTP/2 301 Moved Permanently
Location: https://blog.crea-troyes.frLe navigateur comprend immédiatement qu’il doit ouvrir une nouvelle adresse. Sans cet en-tête, la redirection ne fonctionnerait pas.
Content-Encoding
Les pages web sont souvent compressées afin de réduire leur taille. Le serveur peut par exemple envoyer :
Content-Encoding: gzipou
Content-Encoding: brLe navigateur décompresse automatiquement les données. Cette compression améliore considérablement les performances d’un site.
Un fichier de 500 Ko peut parfois être réduit à moins de 100 Ko. Le gain est énorme.
Last-Modified
Cet en-tête indique la dernière modification du document.
Last-Modified: Sun, 28 Jun 2026 18:30:00 GMTGrâce à cette information, le navigateur peut demander :
« Ce fichier a-t-il changé depuis ma dernière visite ? »
Si la réponse est non, le serveur évite de renvoyer le fichier.
- Le chargement est donc beaucoup plus rapide.
ETag
L’ETag poursuit le même objectif que Last-Modified, mais avec une approche différente :
ETag: "a85f7d2"Au lieu de comparer une date, le serveur attribue un identifiant unique à la ressource. Si cet identifiant est toujours le même, le navigateur sait que le contenu n’a pas changé.
Cela permet d’éviter des téléchargements inutiles et d’améliorer les performances.
Strict-Transport-Security (HSTS)
Voici un en-tête très important pour la sécurité.
Strict-Transport-Security: max-age=31536000Son rôle est simple : Il indique au navigateur qu’il ne devra plus jamais utiliser une connexion HTTP non sécurisée pendant la durée indiquée.
Autrement dit, toutes les futures connexions devront obligatoirement utiliser HTTPS. Cela réduit les risques d’interception des communications.
X-Content-Type-Options
Cet en-tête est souvent présent sur les sites correctement sécurisés.
X-Content-Type-Options: nosniffIl interdit au navigateur de deviner le type réel d’un fichier. Le navigateur doit respecter strictement la valeur de Content-Type.
Cette protection limite certains types d’attaques.
X-Frame-Options
Un autre en-tête de sécurité très répandu.
X-Frame-Options: SAMEORIGINIl empêche votre site d’être intégré dans une balise <iframe> provenant d’un autre domaine.
Cette protection limite certaines attaques de type Clickjacking, où un utilisateur est incité à cliquer sur des éléments invisibles ou trompeurs.
Content-Security-Policy (CSP)
C’est l’un des en-têtes de sécurité les plus puissants. Il peut être impressionnant au premier abord.
Voici un exemple simplifié.
Content-Security-Policy: default-src 'self'Cette règle indique que le navigateur ne doit charger les ressources (scripts, images, feuilles de style, etc.) que depuis le site lui-même.
Une politique CSP bien configurée permet de limiter fortement les attaques par injection de code malveillant, notamment les attaques XSS (Cross-Site Scripting).
Sa configuration peut devenir complexe sur des sites riches en contenus externes, mais elle constitue un excellent moyen de renforcer la sécurité.
Access-Control-Allow-Origin
Cet en-tête intervient dans les échanges entre différents sites web :
Access-Control-Allow-Origin: *Il indique que toutes les origines sont autorisées à accéder à la ressource. Dans d’autres cas, le serveur peut limiter l’accès à un domaine précis.
Cette politique, appelée CORS (Cross-Origin Resource Sharing), protège les utilisateurs contre certaines utilisations abusives des ressources d’un site par un autre.
Faut-il tous les connaître ?
La réponse est non.
Même les développeurs expérimentés consultent régulièrement la documentation lorsqu’ils rencontrent un en-tête peu courant.
L’essentiel est de comprendre leur logique : certains servent à améliorer les performances, d’autres à renforcer la sécurité, à gérer le cache, à identifier le type de contenu ou encore à faciliter les échanges entre le navigateur et le serveur.
À force de les rencontrer dans vos projets, ils deviendront de plus en plus familiers.
Cas pratiques : apprendre à lire les en-têtes HTTP
Maintenant que vous connaissez les principaux en-têtes HTTP, il est temps de les mettre en pratique.
L’objectif n’est pas de retenir chaque ligne par cœur, mais plutôt d’apprendre à les interpréter. Avec un peu d’expérience, vous serez capable d’identifier rapidement si une réponse HTTP est correcte ou si quelque chose mérite votre attention.
Voyons ensemble plusieurs situations que vous rencontrerez probablement au cours de vos développements.
Cas pratique n°1 : une page web classique
Imaginons que vous exécutiez la commande suivante :
curl -I https://blog.crea-troyes.frVous obtenez une réponse ressemblant à ceci :
HTTP/2 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 24567
Cache-Control: max-age=3600
Content-Encoding: gzip
Date: Mon, 29 Jun 2026 10:15:42 GMT
Server: nginxÀ première vue, cette réponse peut sembler difficile à comprendre. Pourtant, chaque ligne raconte une partie de l’histoire.
- La première ligne indique que tout s’est correctement déroulé. Le serveur a trouvé la page et l’a renvoyée sans erreur.
- Ensuite, le navigateur apprend qu’il s’agit d’un document HTML encodé en UTF-8. Il sait donc exactement comment afficher les caractères accentués.
- La taille du document est également connue grâce à
Content-Length. - Le navigateur découvre ensuite qu’il peut conserver cette page en mémoire pendant une heure grâce à
Cache-Control. - Enfin, il apprend que le document est compressé avec Gzip avant d’être téléchargé, ce qui réduit le temps de chargement.
En quelques secondes, vous obtenez déjà énormément d’informations sur le fonctionnement du serveur.
Cas pratique n°2 : une redirection
Essayons maintenant cette commande :
curl -IL http://monsite.frLa réponse pourrait ressembler à ceci :
HTTP/1.1 301 Moved Permanently
Location: https://monsite.fr
HTTP/2 200 OK
Content-Type: text/htmlLe serveur a reçu une connexion en HTTP.
Au lieu d’envoyer directement la page, il indique au navigateur :
« Cette page existe toujours, mais elle se trouve désormais en HTTPS. »
Le navigateur suit alors automatiquement cette nouvelle adresse. C’est exactement ce que l’on souhaite aujourd’hui.
Toutes les connexions devraient être redirigées vers HTTPS afin de garantir une communication chiffrée.
Cas pratique n°3 : analyser une API
Prenons maintenant un service qui renvoie du JSON.
curl -i https://jsonplaceholder.typicode.com/posts/1Vous pourriez obtenir :
HTTP/1.1 200 OK
Content-Type: application/json
{
...
}Même sans regarder le contenu, vous savez déjà qu’il ne s’agit pas d’une page HTML. Le serveur vous envoie un document JSON.
Cette simple information permet à votre application de traiter correctement les données reçues.
Cas pratique n°4 : un téléchargement
Supposons que vous téléchargiez un fichier PDF.
La réponse peut contenir :
Content-Type: application/pdfLe navigateur comprend immédiatement qu’il s’agit d’un document PDF.
Certains serveurs ajoutent également :
Content-Disposition: attachmentDans ce cas, le navigateur propose directement le téléchargement au lieu d’ouvrir le document.
👉 Découvrez comment transformer un simple lien HTML en lien de téléchargement
Cas pratique n°5 : une image
Lorsque vous affichez une image, la réponse peut contenir :
Content-Type: image/jpegLe navigateur sait qu’il doit afficher une image.
Si le serveur envoyait par erreur :
Content-Type: text/htmlLe navigateur tenterait d’interpréter l’image comme une page web. Le résultat serait évidemment incorrect.
On comprend alors toute l’importance de cet en-tête.
Comment analyser rapidement une réponse HTTP ?
Lorsque vous consultez des en-têtes HTTP, inutile de lire chaque ligne dans l’ordre.
Avec l’expérience, vous développerez une sorte de méthode.
Personnellement, je regarde généralement les informations dans cet ordre :
- Le code HTTP.
- Le type du contenu.
- Les redirections éventuelles.
- Le cache.
- Les en-têtes de sécurité.
- Les cookies.
- Les informations diverses.
Cette méthode permet de repérer rapidement un problème.
Par exemple :
- une erreur 404 saute immédiatement aux yeux
- une absence de compression est vite repérée
- un mauvais
Content-Typeest immédiatement visible.
Les erreurs les plus fréquentes
Les débutants rencontrent souvent les mêmes difficultés.
Voici les principales.
Confondre les en-têtes et le contenu
C’est probablement l’erreur la plus fréquente. Prenons cette réponse :
HTTP/2 200 OK
Content-Type: text/html
<html>
...Tout ce qui se trouve avant la ligne vide correspond aux en-têtes. Tout ce qui suit constitue le contenu.
Cette distinction est essentielle.
Penser que tous les sites utilisent les mêmes en-têtes HTTP
Chaque serveur est configuré différemment. Deux sites peuvent donc renvoyer des listes d’en-têtes complètement différentes.
C’est parfaitement normal.
Vouloir mémoriser tous les en-têtes
Il en existe plusieurs dizaines. Certains sont très rares. Même les professionnels ne les connaissent pas tous.
Ils consultent régulièrement la documentation. L’objectif n’est donc pas de tout apprendre par cœur.
Oublier les en-têtes de sécurité
Beaucoup de développeurs se concentrent uniquement sur le HTML et le CSS. Pourtant, une grande partie de la sécurité d’un site repose sur les en-têtes HTTP.
Un simple oubli peut parfois ouvrir la porte à certaines attaques.
Les bonnes pratiques
Au fil de vos projets, quelques habitudes vous feront gagner énormément de temps.
La première consiste à vérifier systématiquement les en-têtes après la mise en ligne d’un nouveau site.
Quelques secondes suffisent pour contrôler :
- le code HTTP
- le type de contenu
- la compression
- le cache
- les principaux en-têtes de sécurité
Cette vérification permet souvent de détecter des erreurs avant même que les visiteurs ne les rencontrent.
Ensuite, prenez l’habitude d’utiliser les outils de développement de votre navigateur. Ils affichent les en-têtes de manière très claire et permettent de suivre toutes les requêtes en temps réel.
Enfin, n’hésitez pas à utiliser curl depuis le terminal. C’est un excellent réflexe pour effectuer un diagnostic rapide, sans avoir besoin d’ouvrir un navigateur.
Les en-têtes HTTP et le SEO
On parle souvent de référencement naturel en pensant uniquement aux balises HTML ou au contenu des pages.
Pourtant, plusieurs en-têtes HTTP influencent également le SEO.
Par exemple, les redirections 301 permettent d’indiquer à Google qu’une page a changé d’adresse de manière définitive. Elles évitent la perte de popularité lors d’une migration de site.
Le cache, lorsqu’il est correctement configuré, améliore les performances de chargement. Or, la vitesse d’affichage est un critère pris en compte par les moteurs de recherche.
La compression Gzip ou Brotli réduit la quantité de données échangées entre le serveur et le navigateur, ce qui accélère également le chargement des pages.
Enfin, certains en-têtes de sécurité, comme Strict-Transport-Security, participent à une meilleure sécurisation du site. Même s’ils n’ont pas un impact direct sur le positionnement, ils contribuent à offrir une expérience plus fiable aux visiteurs.
En résumé, les en-têtes HTTP ne remplacent pas un bon contenu ou une structure HTML de qualité, mais ils font partie des nombreux éléments techniques qui participent à l’optimisation globale d’un site web.
Aller encore plus loin
Une fois à l’aise avec les en-têtes HTTP, vous pourrez approfondir plusieurs sujets passionnants.
Vous découvrirez par exemple :
- le fonctionnement complet du protocole HTTP/2 et de HTTP/3
- les requêtes
GET,POST,PUT,PATCHetDELETEutilisées par les API REST - le fonctionnement des cookies de session
- les mécanismes de cache avancés avec
ETagetIf-Modified-Since - les politiques CORS
- les politiques CSP
- l’analyse des requêtes réseau dans les applications JavaScript modernes
- les outils de cybersécurité capables d’inspecter automatiquement les réponses HTTP
Toutes ces notions s’appuient sur les bases que vous venez d’apprendre.
Comment voir les en-têtes HTTP d’un site web ?
Le moyen le plus simple consiste à utiliser les outils de développement de votre navigateur (touche F12), puis à ouvrir l’onglet Réseau (Network). Vous pouvez également utiliser la commande curl -I dans un terminal pour afficher rapidement les en-têtes de réponse d’un serveur.
Pourquoi les en-têtes HTTP sont-ils importants ?
Les en-têtes HTTP indiquent au navigateur comment traiter une ressource. Ils servent notamment à gérer le cache, les cookies, les redirections, la sécurité ou encore le type de contenu envoyé. Ils jouent donc un rôle essentiel dans les performances et le bon fonctionnement d’un site web.
Les en-têtes HTTP ont-ils un impact sur le référencement naturel (SEO) ?
Oui, certains en-têtes HTTP influencent indirectement le SEO. Une bonne gestion des redirections, de la compression, du cache ou du protocole HTTPS contribue à améliorer les performances et l’expérience utilisateur, deux éléments importants pour les moteurs de recherche.
Les en-têtes HTTP sont souvent invisibles pour les internautes, mais ils sont omniprésents dans les échanges entre un navigateur et un serveur. Ils indiquent comment interpréter une ressource, comment la mettre en cache, comment sécuriser la connexion ou encore comment gérer les cookies et les redirections.
Au début, leur lecture peut sembler impressionnante. Pourtant, vous avez vu qu’il suffit de comprendre quelques en-têtes essentiels pour déjà mieux analyser le fonctionnement d’un site web. Avec un navigateur, la commande curl ou quelques lignes de PHP, vous êtes désormais capable de récupérer ces informations et d’en tirer des conclusions utiles.
Ne cherchez pas à tout retenir dès aujourd’hui. L’important est de prendre l’habitude d’observer les en-têtes lorsque vous développez un site, testez une API ou analysez un problème. Petit à petit, certains noms comme Content-Type, Cache-Control, Set-Cookie ou Content-Security-Policy deviendront familiers, et vous les reconnaîtrez presque instinctivement.
Finalement, apprendre à lire les en-têtes HTTP, c’est un peu comme apprendre à lire entre les lignes d’une conversation. Le contenu d’une page raconte une histoire aux visiteurs, tandis que les en-têtes racontent au navigateur comment cette histoire doit être transmise. En maîtrisant ces deux aspects, vous franchissez une nouvelle étape dans votre compréhension du Web et vous disposez d’un véritable atout pour développer des sites plus performants, mieux sécurisés et plus faciles à maintenir.

Fondateur de l’agence Créa-troyes, affiliée France Num
Intervenant en Freelance.
Contactez-moi