Vous développez un site web, vous analysez vos statistiques ou vous testez deux versions d’une interface… et une question revient souvent : les résultats sont-ils vraiment fiables ou est-ce simplement du hasard ? C’est exactement là qu’intervient la loi de Student.
- Comprendre simplement ce qu’est la loi de Student et pourquoi elle est essentielle pour interpréter correctement des données lorsque l’on dispose de peu de mesures.
- Savoir analyser des résultats réels (tests A/B, performances d’un site, comportement utilisateur) afin de distinguer une vraie amélioration d’un simple effet du hasard.
- Découvrir comment appliquer concrètement cette approche statistique dans vos projets web grâce à des exemples pratiques et des extraits de code.
Derrière ce nom un peu mystérieux se cache un outil statistique très utilisé pour analyser de petits échantillons de données. En développement web, elle peut vous aider à interpréter des tests A/B, analyser des performances ou valider des résultats expérimentaux.
Même si le mot statistique peut faire peur, vous n’avez pas besoin d’un doctorat en mathématiques pour comprendre la loi de Student. Dans ce tutoriel, nous allons partir de zéro, expliquer chaque concept simplement et voir comment l’utiliser concrètement avec du code.
- Comprendre la loi de Student (sans se faire un nœud au cerveau)
- Le problème que résout la loi de Student
- La formule de la loi de Student
- Exemple simple pour comprendre
- La notion de degrés de liberté
- Visualiser la distribution de Student
- Application concrète en développement web
- Calculer un test de Student en JavaScript
- Calculer l’écart-type en JavaScript
- Calculer la statistique t
- Utiliser Python pour aller plus loin
- Exemple concret : optimisation d’un site
- Les erreurs fréquentes avec la loi de Student
Comprendre la loi de Student (sans se faire un nœud au cerveau)
Avant de parler de formule ou de programmation, prenons une situation très concrète. Imaginez que vous testez deux boutons sur votre site :
- un bouton bleu
- un bouton vert
Après 20 visiteurs, vous obtenez :
- bouton bleu : 8 clics
- bouton vert : 11 clics
La question est simple : le bouton vert est-il vraiment meilleur… ou est-ce juste un coup de chance ?
Si vous aviez 1 million de visiteurs, la réponse serait évidente. Mais avec 20 visiteurs seulement, c’est beaucoup moins clair. C’est exactement pour ce type de situation que la loi de Student a été créée.
Petite histoire : pourquoi ça s’appelle “Student” ?
Fun fact : Student n’est pas une personne.
La loi a été développée en 1908 par un statisticien nommé William Sealy Gosset qui travaillait pour la brasserie Guinness. Oui, la bière. 🍺
Son problème était simple : il devait analyser de petits échantillons de production pour vérifier la qualité de la bière. Mais Guinness interdisait aux employés de publier des recherches sous leur vrai nom.
Il signa donc ses travaux sous le pseudonyme : Student
Depuis, on parle de :
- la loi de Student
- ou distribution t de Student
Le problème que résout la loi de Student
En statistique, on veut souvent estimer la moyenne d’un phénomène. Par exemple :
- temps moyen passé sur une page
- nombre moyen de clics
- temps de chargement moyen
- conversion moyenne
Mais il y a un problème. Si vous avez peu de données, votre estimation est incertaine.
Prenons un exemple : Le temps de chargement mesuré sur 5 visiteurs :
1.2s
1.4s
1.1s
2.0s
1.3sLa moyenne est environ :
1.4 secondesMais avec seulement 5 mesures, cette moyenne peut être très approximative.
- La loi de Student permet de mesurer cette incertitude.
La formule de la loi de Student
La statistique t se calcule avec la formule suivante :
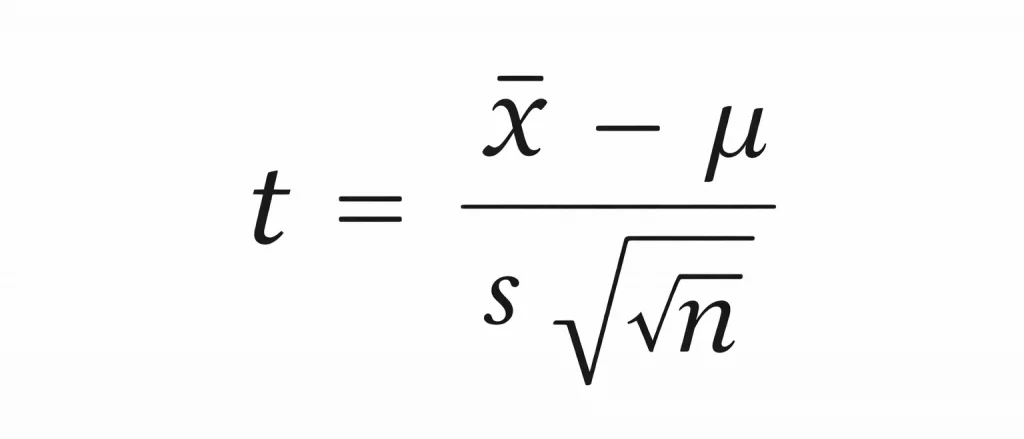
Ne paniquez pas. Regardons chaque élément tranquillement.
x̄ (x barre)
c’est la moyenne observée dans votre échantillon.
μ (mu)
c’est la moyenne théorique que vous voulez tester.
s
c’est l’écart-type de l’échantillon.
n
c’est le nombre d’observations.
En résumé, la formule compare :
la moyenne observée
avec la moyenne attendue
en tenant compte de la variabilité des données
Exemple simple pour comprendre
Supposons que vous voulez tester si votre page charge en 1 seconde en moyenne.
Vous mesurez 10 visites et obtenez :
1.1
0.9
1.2
1.3
1.0
0.8
1.1
1.2
1.0
0.9La moyenne est :
1.05 secondesCe n’est pas exactement 1 seconde.
Mais la vraie question est : est-ce une différence significative ?
- C’est là que la loi de Student intervient.
Elle calcule une statistique t, puis on la compare à une table de Student.
Selon le résultat, on peut conclure :
- la différence est significative
- ou elle est due au hasard
La notion de degrés de liberté
Quand on utilise la loi de Student, un terme revient souvent : les degrés de liberté
En pratique, ils valent :
n − 1Si vous avez :
10 mesuresAlors les degrés de liberté sont :
9Pourquoi ? Parce que la moyenne impose une contrainte sur les données. Une valeur devient dépendante des autres.
Ce concept peut sembler abstrait, mais dans la pratique :
degrés de liberté = nombre de données − 1
Et c’est ce nombre qui permet de choisir la bonne distribution t.
Visualiser la distribution de Student
La distribution t ressemble beaucoup à une courbe normale (courbe en cloche).
Mais elle est :
- plus large
- avec des extrémités plus épaisses
Parce qu’avec peu de données, l’incertitude est plus grande. Quand le nombre d’observations augmente :
- la distribution de Student se rapproche de la loi normale.
En pratique :
| nombre de données | distribution |
|---|---|
| petit échantillon | loi de Student |
| grand échantillon | loi normale |
Application concrète en développement web
La loi de Student apparaît souvent dans :

Des formations informatique pour tous !
Débutant ou curieux ? Apprenez le développement web, le référencement, le webmarketing, la bureautique, à maîtriser vos appareils Apple et bien plus encore…
Formateur indépendant, professionnel du web depuis 2006, je vous accompagne pas à pas et en cours particulier, que vous soyez débutant ou que vous souhaitiez progresser. En visio, à votre rythme, et toujours avec pédagogie.
Découvrez mes formations Qui suis-je ?tests A/B
Comparer deux versions :
- bouton rouge
- bouton bleu
👉 Pour en savoir plus : Test statistique et A/B Testing
analyse de performance
Comparer :
- temps de chargement avant optimisation
- temps de chargement après optimisation
analyse UX
Comparer :
- temps moyen pour remplir un formulaire
- taux de clic sur deux designs
Sans outil statistique, vous pourriez tirer de mauvaises conclusions.
Calculer un test de Student en JavaScript
Prenons un exemple simple. Vous testez deux versions d’un bouton.
Données version A
[12, 14, 11, 15, 13]Données version B
[18, 20, 17, 19, 21]Ces valeurs représentent le nombre de clics par session.
Voici un exemple simple de calcul de moyenne en JavaScript :
function moyenne(data) {
let somme = data.reduce((a,b) => a + b, 0);
return somme / data.length;
}
let A = [12,14,11,15,13];
let B = [18,20,17,19,21];
console.log("Moyenne A :", moyenne(A));
console.log("Moyenne B :", moyenne(B));Résultat :
Moyenne A : 13
Moyenne B : 19La différence semble importante.
Mais est-elle statistiquement significative ?
Pour répondre à cette question, on utilise un test t de Student.
Calculer l’écart-type en JavaScript
Avant le test, nous devons calculer l’écart-type.
function ecartType(data) {
let m = moyenne(data);
let variance = data.reduce((sum, value) => {
return sum + Math.pow(value - m, 2);
}, 0) / (data.length - 1);
return Math.sqrt(variance);
}Puis :
console.log(ecartType(A));
console.log(ecartType(B));Ce calcul mesure la dispersion des données.
Plus l’écart-type est grand, plus les résultats varient.
Calculer la statistique t
Voici un exemple simplifié.
function tStatistic(A, B){
let m1 = moyenne(A);
let m2 = moyenne(B);
let s1 = ecartType(A);
let s2 = ecartType(B);
let n1 = A.length;
let n2 = B.length;
let numerateur = m1 - m2;
let denominateur = Math.sqrt(
(s1*s1)/n1 + (s2*s2)/n2
);
return numerateur / denominateur;
}Puis :
console.log(tStatistic(A,B));Le résultat donne la statistique t.
Ensuite on la compare à une valeur critique de Student.
Utiliser Python pour aller plus loin
Python possède des bibliothèques statistiques très pratiques. Par exemple avec SciPy :
from scipy import stats
A = [12,14,11,15,13]
B = [18,20,17,19,21]
t_stat, p_value = stats.ttest_ind(A,B)
print("t =", t_stat)
print("p =", p_value)Le p-value indique la probabilité que la différence soit due au hasard.
En général :
p < 0.05signifie que la différence est statistiquement significative.
Exemple concret : optimisation d’un site
Supposons que vous optimisez un site pour améliorer le temps de chargement.
Vous mesurez :
Avant optimisation
2.1
2.3
2.2
2.5
2.0Après optimisation
1.8
1.7
1.9
1.6
1.8La différence semble évidente.
Mais grâce à la loi de Student, vous pouvez prouver que l’amélioration est statistiquement réelle.
C’est particulièrement utile pour :
- convaincre un client
- documenter une optimisation
- justifier une décision technique
Les erreurs fréquentes avec la loi de Student
Quand on débute, certaines erreurs sont fréquentes.
Par exemple :
→ échantillon trop petit
Avec 3 ou 4 données, les conclusions peuvent être trompeuses.
→ mélanger des populations différentes
Comparer des données non comparables fausse les résultats.
→ interpréter mal la p-value
Une p-value faible ne signifie pas que votre hypothèse est vraie.
Elle signifie seulement :
que la différence observée a peu de chances d’être due au hasard.
La loi de Student peut sembler impressionnante au premier abord. Pourtant, une fois expliquée simplement, elle devient un outil incroyablement utile pour tout développeur web curieux de comprendre ses données.
Que vous analysiez des tests A/B, des performances ou des comportements utilisateurs, cette méthode vous permet de prendre des décisions basées sur des faits plutôt que sur des impressions. Et dans un monde où chaque optimisation peut améliorer l’expérience utilisateur ou le taux de conversion, c’est un avantage considérable.
La bonne nouvelle, c’est qu’aujourd’hui vous n’avez plus besoin de calculer ces statistiques à la main. JavaScript, Python ou de nombreuses bibliothèques le font pour vous. Mais comprendre ce qui se cache derrière la loi de Student reste essentiel. C’est cette compréhension qui vous permettra d’interpréter correctement vos résultats… et d’éviter de tirer des conclusions un peu trop rapides.
Et qui sait ? Peut-être que la prochaine fois que vous analyserez les statistiques de votre site, vous aurez une petite pensée pour la brasserie Guinness, où tout a commencé.

Fondateur de l’agence Créa-troyes, affiliée France Num
Intervenant en Freelance.
Contactez-moi