Si vous avez déjà eu l’impression que votre site WordPress ressemble à une ville… sans plan, vous n’êtes pas seul. On ajoute des articles, on crée des pages, on fait quelques liens “au feeling”… et un jour, on se demande pourquoi certaines pages ne décollent pas sur Google. La cartographie du maillage interne va vous donner ce plan. L’idée est simple : transformer votre site en un graphe (un réseau) où chaque page est un point, et chaque lien interne est une flèche.
Et là, magie : on voit immédiatement les hubs (pages centrales), les pages orphelines, les pages “cul-de-sac”, et même les zones où le maillage interne est trop pauvre.
- Visualiser clairement la structure de votre site WordPress pour identifier les pages centrales, les contenus isolés et les déséquilibres de maillage.
- Transformer vos données en carte exploitable afin de prendre des décisions SEO fiables.
- Optimiser votre maillage interne de manière stratégique pour renforcer la visibilité des pages importantes et améliorer la circulation des visiteurs et des robots de Google.
Dans ce tutoriel, on part de zéro, on va génèrer deux fichiers CSV depuis WordPress (nodes.csv et edges.csv) avec un script PHP maison, puis on va construire la carte dans Gephi, étape par étape, jusqu’à obtenir un rendu lisible et exploitable.
Comprendre la cartographie du maillage interne
Sur un site WordPress, le maillage interne correspond à tous les liens qui pointent d’une page du site vers une autre page du même site.
Exemples concrets :
- Dans un article “Apprendre le CSS”, vous ajoutez un lien vers “Les sélecteurs CSS”.
- Sur une page “Services”, vous renvoyez vers une page “Contact”.
- Dans un tutoriel, vous faites un lien vers un chapitre précédent.
Chaque lien interne aide :
- les visiteurs à naviguer,
- Google à explorer le site,
- vos pages à se transmettre de la popularité (ce qu’on appelle souvent, de façon vulgarisée, le “jus SEO”).
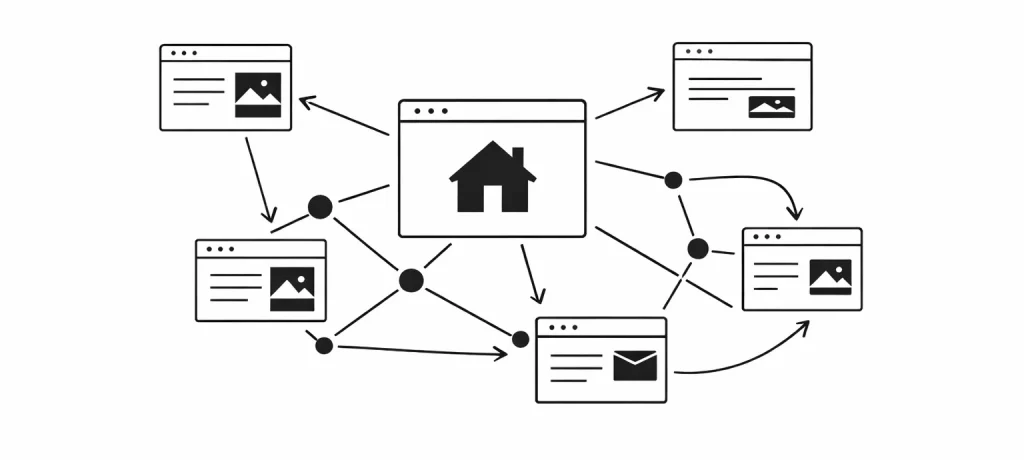
👉 Tout savoir sur Le maillage interne d’un site web.
Pourquoi cartographier ce maillage ?
Parce que lire vos liens un par un dans l’éditeur WordPress, c’est comme essayer de comprendre une carte routière… en regardant uniquement la liste des rues.
Avec une cartographie du maillage interne, vous allez pouvoir :
- repérer les pages orphelines (aucun lien entrant),
- repérer les pages sans lien sortant (des impasses),
- voir les pages très centrales (celles qui reçoivent et envoient beaucoup de liens),
- identifier les “silos” (des groupes de pages très liées entre elles mais isolées du reste),
- comprendre pourquoi certaines pages peinent à être indexées ou à performer.
Et surtout : vous allez passer de “je pense que…” à “je vois clairement que…”.
Ce que Gephi va vous apporter
Gephi est un logiciel de visualisation de réseaux. En clair, il sert à dessiner des graphes à partir de données.
Votre site devient un réseau :
- Noeuds (nodes) : vos pages / articles
- Liens (edges) : vos liens internes
Gephi permet ensuite de :
- appliquer des mises en page automatiques (les fameux “layouts”),
- colorer et dimensionner automatiquement selon l’importance,
- calculer des indicateurs (degrés, centralité, modularité),
- filtrer pour rendre la carte lisible,
- exporter une image propre.
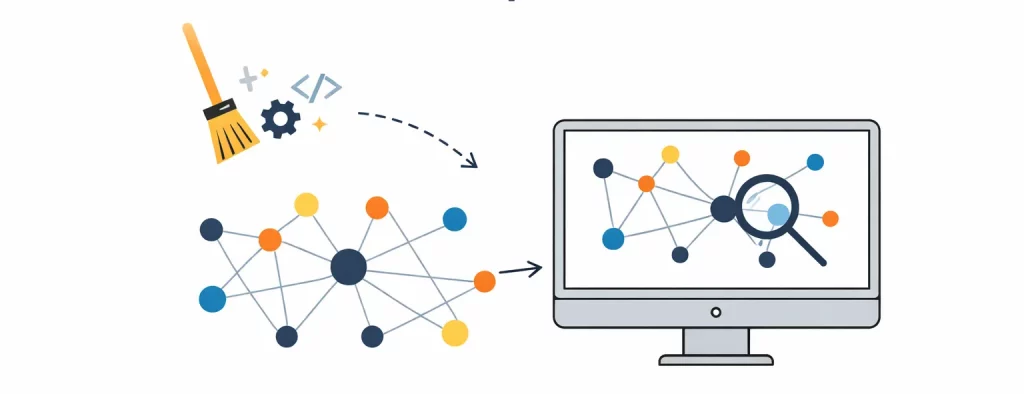
Ce que vous allez “voir” en un coup d’œil
Imaginez une carte où :
- une grosse planète au centre = une page qui reçoit beaucoup de liens internes,
- un petit point isolé sur le côté = page orpheline ou quasi orpheline,
- une grappe dense = un groupe d’articles qui se linkent beaucoup entre eux (un silo),
- des flèches dans tous les sens = navigation forte, mais parfois un peu chaotique.
C’est très visuel, et franchement… assez satisfaisant quand on commence à comprendre ce qu’on regarde.
Générer les fichiers CSV depuis WordPress (nodes.csv et edges.csv)
Nous allons coder un script PHP qui va parcourir vos contenus WordPress, récupèrer les pages et articles publiés, extraire les liens internes dans le HTML, puis exporter deux fichiers CSV.
Avant d’expliquer la procédure d’utilisation, on va d’abord comprendre ce que fait le code, parce que c’est là que tout devient clair.
<?php
// Charger WordPress
require_once(__DIR__ . '/wp-load.php');
// Sécurité simple (optionnel)
if (!current_user_can('administrator')) {
die('Accès refusé.');
}
// Récupération des posts et pages publiés
$args = [
'post_type' => ['post', 'page'],
'post_status' => 'publish',
'posts_per_page' => -1
];
$posts = get_posts($args);
$site_url = home_url();
$nodes = [];
$edges = [];
// Construire tableau des nodes
foreach ($posts as $post) {
$url = get_permalink($post->ID);
$nodes[$url] = [
'id' => $url,
'label' => html_entity_decode($post->post_title, ENT_QUOTES)
];
}
// Extraction des liens éditoriaux
foreach ($posts as $post) {
$source_url = get_permalink($post->ID);
$content = $post->post_content;
if (empty($content)) continue;
libxml_use_internal_errors(true);
$dom = new DOMDocument();
$dom->loadHTML('<?xml encoding="utf-8" ?>' . $content);
$links = $dom->getElementsByTagName('a');
foreach ($links as $link) {
$href = $link->getAttribute('href');
if (empty($href)) continue;
// Normaliser URL
$href = strtok($href, '#'); // enlever ancres
$href = strtok($href, '?'); // enlever paramètres
// Vérifier si lien interne
if (strpos($href, $site_url) === 0) {
// Vérifier que la cible existe dans nos nodes
if (isset($nodes[$href])) {
$edges[] = [
'source' => $source_url,
'target' => $href
];
}
}
}
}
// Génération nodes.csv
$nodes_file = fopen('nodes.csv', 'w');
fputcsv($nodes_file, ['id', 'label']);
foreach ($nodes as $node) {
fputcsv($nodes_file, [$node['id'], $node['label']]);
}
fclose($nodes_file);
// Génération edges.csv
$edges_file = fopen('edges.csv', 'w');
fputcsv($edges_file, ['source', 'target']);
foreach ($edges as $edge) {
fputcsv($edges_file, [$edge['source'], $edge['target']]);
}
fclose($edges_file);
echo "Export terminé : nodes.csv et edges.csv générés.";Explication de notre code PHP
En premier lieu, charger WordPress
require_once(__DIR__ . '/wp-load.php');Cette ligne charge WordPress “de l’intérieur”. Sans ça, les fonctions WordPress comme get_posts(), home_url() ou get_permalink() ne fonctionneraient pas.
En gros : vous dites à PHP “je veux accéder au moteur WordPress et à sa base de données”.
Important, on sécurise l’accès de notre export :
if (!current_user_can('administrator')) {
die('Accès refusé.');
}- Ici, on empêche n’importe qui de lancer l’export.
Pourquoi ? Parce que le script peut révéler la structure du site (URLs, titres, liens internes). Ce n’est pas dramatique, mais autant éviter qu’un visiteur tombe dessus par hasard.
Donc : seul un administrateur connecté peut exécuter le script.
Récupérer toutes les pages et articles publiés
$args = [
'post_type' => ['post', 'page'],
'post_status' => 'publish',
'posts_per_page' => -1
];
$posts = get_posts($args);Vous demandez à WordPress :
- donne-moi tous les contenus de type
post(articles) etpage(pages), - uniquement ceux qui sont publiés,
- sans limite (
-1= tout).
Résultat : $posts contient la liste de vos contenus.
Préparer la base : URL du site + tableaux nodes et edges
$site_url = home_url();
$nodes = [];
$edges = [];$site_urlrécupère l’URL de base, par exemplehttps://blog.crea-troyes.fr.$nodesva contenir tous les noeuds (les pages).$edgesva contenir tous les liens (les relations entre pages).
Construire les noeuds : une ligne par page
foreach ($posts as $post) {
$url = get_permalink($post->ID);
$nodes[$url] = [
'id' => $url,
'label' => html_entity_decode($post->post_title, ENT_QUOTES)
];
}Pour chaque contenu :
get_permalink($post->ID)récupère son URL définitive.- On l’ajoute dans
$nodesavecid: l’URL (unique) etlabel: le titre lisible (décodé pour éviter les&,"etc.)
On utilise l’URL comme identifiant parce que c’est stable et unique. Deux pages peuvent avoir des titres proches, mais pas la même URL.
Extraire les liens internes dans le contenu HTML
On passe maintenant à la partie la plus importante : lire le contenu de chaque page et y trouver les balises <a href="...">.
foreach ($posts as $post) {
$source_url = get_permalink($post->ID);
$content = $post->post_content;
if (empty($content)) continue;$source_url: l’URL de la page source (celle qui contient les liens).$content: son contenu HTML.- Si le contenu est vide, on saute (pas la peine de chercher des liens dans le vide).
Utiliser DOMDocument pour analyser le HTML
libxml_use_internal_errors(true);
$dom = new DOMDocument();
$dom->loadHTML('<?xml encoding="utf-8" ?>' . $content);
$links = $dom->getElementsByTagName('a');Ici, vous utilisez DOMDocument, une classe PHP très pratique pour lire du HTML proprement.
libxml_use_internal_errors(true)évite que PHP vous spamme avec des warnings si le HTML n’est pas parfait (WordPress produit parfois du HTML pas totalement “académique”).loadHTML(...)charge le contenu.getElementsByTagName('a')récupère toutes les balises<a>.
Donc à ce stade, $links = la liste de tous les liens cliquables du contenu.
Parcourir chaque lien et récupérer son href
foreach ($links as $link) {
$href = $link->getAttribute('href');
if (empty($href)) continue;$href= l’URL cible du lien.- Si vide, on ignore.
Normaliser l’URL : enlever ancres et paramètres
$href = strtok($href, '#'); // enlever ancres
$href = strtok($href, '?'); // enlever paramètresExemple :
https://monsite.fr/article/#section2devienthttps://monsite.fr/article/https://monsite.fr/article/?utm_source=...devienthttps://monsite.fr/article/
C’est important parce que pour une cartographie du maillage interne, on veut considérer que la page est la même, même si le lien a une ancre ou un paramètre.
- Sinon, vous auriez des “faux noeuds” en double, et Gephi deviendrait illisible.
Vérifier que c’est un lien interne
if (strpos($href, $site_url) === 0) {Cette condition signifie :
- si l’URL commence par l’URL du site, alors c’est interne.
Donc :
https://blog.crea-troyes.fr/mon-article= internehttps://google.com/...= externe
Vérifier que la cible existe dans les noeuds
if (isset($nodes[$href])) {
$edges[] = [
'source' => $source_url,
'target' => $href
];
}C’est une étape très importante.
Même si une page fait un lien vers une URL interne, la cible peut être :
- une page supprimée,
- une URL mal tapée,
- une catégorie, un tag, un auteur… (qui ne sont pas dans
postetpage), - un custom post type non inclus.
Avec isset($nodes[$href]), vous ne gardez que les liens vers des pages/articles que vous avez bien exportés comme noeuds.
Ensuite vous ajoutez une relation :
source= page qui fait le lientarget= page liée
- Et là, vous venez de créer l’équivalent d’une flèche sur votre futur graphe.
Exporter nodes.csv
$nodes_file = fopen('nodes.csv', 'w');
fputcsv($nodes_file, ['id', 'label']);
foreach ($nodes as $node) {
fputcsv($nodes_file, [$node['id'], $node['label']]);
}
fclose($nodes_file);Vous créez un fichier CSV avec :
- une première ligne d’en-têtes :
id,label - puis une ligne par page.
Exemple de sortie pour ce fichier :
id,label
https://monsite.fr/accueil,Accueil
https://monsite.fr/contact,Contact
https://monsite.fr/apprendre-css,Apprendre le CSSExporter edges.csv
$edges_file = fopen('edges.csv', 'w');
fputcsv($edges_file, ['source', 'target']);
foreach ($edges as $edge) {
fputcsv($edges_file, [$edge['source'], $edge['target']]);
}
fclose($edges_file);Même principe, mais pour les liens :
source,target
https://monsite.fr/apprendre-css,https://monsite.fr/les-selecteurs-css
https://monsite.fr/apprendre-css,https://monsite.fr/apprendre-htmlChaque ligne = une flèche.
Enfin, le message final
echo "Export terminé : nodes.csv et edges.csv générés.";Simple confirmation pour indiquer que tout s’est bien passé.
Pourquoi un fichier nodes.csv et edges.csv
Pourquoi utiliser deux fichiers :
nodes.csvetedges.csv?
Lorsque l’on débute avec Gephi, une question revient souvent : pourquoi ne pas tout mettre dans un seul fichier ? Après tout, vos pages et vos liens font partie du même site… alors pourquoi les séparer ?
La réponse est simple : parce que Gephi fonctionne comme un outil de cartographie de réseau. Et dans un réseau, il y a toujours deux éléments distincts :
- les points (les entités),
- les connexions (les relations entre ces entités).
Dans le cas de la cartographie du maillage interne d’un site WordPress :
- les pages et articles sont les points → ce sont les nodes ;
- les liens internes sont les connexions → ce sont les edges.
Le rôle du fichier nodes.csv
Le fichier nodes.csv contient la liste complète des pages que vous voulez représenter sur la carte. Chaque ligne correspond à une page. Concrètement, vous fournissez à Gephi :
- un identifiant unique (ici l’URL),
- un label lisible (le titre de la page).
Sans ce fichier, Gephi ne saurait pas quels “points” afficher. Ce serait comme vouloir dessiner une carte routière sans connaître les villes.
Autrement dit, nodes.csv définit les éléments du réseau.
Le rôle du fichier edges.csv
Le fichier edges.csv, lui, définit les relations entre ces éléments.
Chaque ligne indique :
- une page source,
- une page cible.
Cela signifie :
“La page A fait un lien vers la page B”.
Sans ce fichier, vous auriez simplement une liste de pages isolées. Aucun lien. Aucun réseau. Aucune structure.
Ce serait comme avoir une liste de villes… mais aucune route entre elles.
Pourquoi Gephi exige cette séparation
Gephi est conçu pour analyser des réseaux complexes. Il doit pouvoir :
- calculer combien de liens reçoit une page (liens entrants),
- calculer combien elle en envoie (liens sortants),
- détecter des groupes de pages fortement liées,
- mesurer la centralité,
- visualiser les flux.
Pour faire ces calculs correctement, il a besoin :
- d’une table des entités (les nodes),
- d’une table des relations (les edges).
C’est cette structure en deux fichiers qui permet à Gephi de comprendre votre site comme un graphe orienté, c’est-à-dire un réseau où les liens ont un sens.
Une analogie simple pour bien comprendre
Imaginez que vous organisez un événement.
- Vous avez une liste d’invités → c’est votre fichier
nodes.csv. - Vous avez une liste des personnes qui se connaissent entre elles → c’est votre fichier
edges.csv.
Si vous mélangez tout dans un seul tableau, impossible de distinguer clairement qui est une personne et qui est une relation.
En séparant les deux, vous permettez à l’outil d’analyser la structure sociale du groupe. C’est exactement ce que vous faites avec votre site WordPress.

Des formations informatique pour tous !
Débutant ou curieux ? Apprenez le développement web, le référencement, le webmarketing, la bureautique, à maîtriser vos appareils Apple et bien plus encore…
Formateur indépendant, professionnel du web depuis 2006, je vous accompagne pas à pas et en cours particulier, que vous soyez débutant ou que vous souhaitiez progresser. En visio, à votre rythme, et toujours avec pédagogie.
Découvrez mes formations Qui suis-je ?En résumé, si vous voulez cartographier correctement le maillage interne avec Gephi, vous devez fournir :
- les pages (ce qui existe),
- les liens (ce qui relie).
Ce duo est indispensable. Sans lui, il n’y a pas de réseau… donc pas de cartographie possible.
Où mettre ce code dans WordPress et comment l’exécuter
La meilleure approche :
- Créez un fichier à la racine de WordPress, par exemple :
export-maillage.php - Collez le code dedans.
- Lancez-le une fois en étant connecté en admin depuis :
https://votresite.fr/export-maillage.php - Récupérez
nodes.csvetedges.csv(ils se créeront au même endroit que le script, donc souvent à la racine). Vous pouvez les récupérer depuis votre client FTP (Filezilla, …)
Après usage, supprimez le fichier
export-maillage.phpdu serveur. C’est le geste “je range mes outils après bricolage”, et votre site vous dira merci.
Comprendre les CSV avant de les donner à Gephi
Un CSV, c’est quoi ? Un CSV est un fichier texte qui ressemble à un tableau.
- Chaque ligne = une ligne de tableau.
Les colonnes sont séparées par des virgules (ou parfois des points-virgules selon les configurations).
Vous pouvez les ouvrir avec :
- Excel
- Google Sheets
- LibreOffice Calc
- ou même un éditeur de texte.
Ce que représentent vos deux CSV
Dans notre cas, comme vu précédemment :
nodes.csv= la liste des pages (les “points”)edges.csv= la liste des liens internes (les “flèches”)
C’est exactement ce dont Gephi a besoin.
Petit exemple concret d’un mini site pour mieux comprendre
Imaginez un site WordPress avec 4 pages :
- Accueil
- Blog
- Article A
- Contact
Liens :
- Accueil → Blog
- Blog → Article A
- Article A → Contact
- Accueil → Contact
Alors :
nodes.csv aura 4 lignes (plus l’en-tête).
edges.csv aura 4 lignes (plus l’en-tête).
Vous voyez l’idée : plus votre site est gros, plus edges.csv grossit vite.
Cartographier le maillage interne avec Gephi (procédure complète, pas à pas)
On arrive au moment le plus amusant : transformer vos CSV en cartographie visuelle.
Installer Gephi
Téléchargez Gephi depuis le site officiel (recherchez “Gephi download”). Installez-le comme n’importe quel logiciel.
Ensuite, ouvrez Gephi. Vous arrivez sur un écran avec plusieurs onglets (tout en haut à gauche :
- Overview (Vue d’ensemble)
- Data Laboratory (Laboratoire de données)
- Preview (Prévisualisation)
On va utiliser les trois.
Créer un nouveau projet
Dans Gephi :
- File → New Project ou Fichier → Nouveau projet
Gephi travaille par “projet”. C’est votre fichier de travail.
Importer nodes.csv
- Cliquez sur Fichier → Import feuille de calcul.
- Sélectionnez
nodes.csv. - Gephi vous demande le type :
- choisissez Nodes table ou Table de noeuds
- Vérifiez les colonnes :
iddoit être reconnu comme identifiantlabelcomme texte
- Validez l’import.
À ce stade, vous avez les pages, mais aucun lien. Donc l’affichage dans Overview sera soit vide, soit un nuage sans connexions (normal).
Importer edges.csv
Même procédure, mais avec le fichier des liens.
- Cliquez sur Fichier → Import feuille de calcul.
- Sélectionnez
edges.csv - Cette fois, choisissez Edges table ou Table des liens
- Vérifiez que :
sourcecorrespond bien à des ids existantstargetcorrespond bien à des ids existants
- Type de graphe : vous pouvez choisir Directed (dirigé), car un lien a un sens : page A pointe vers page B.
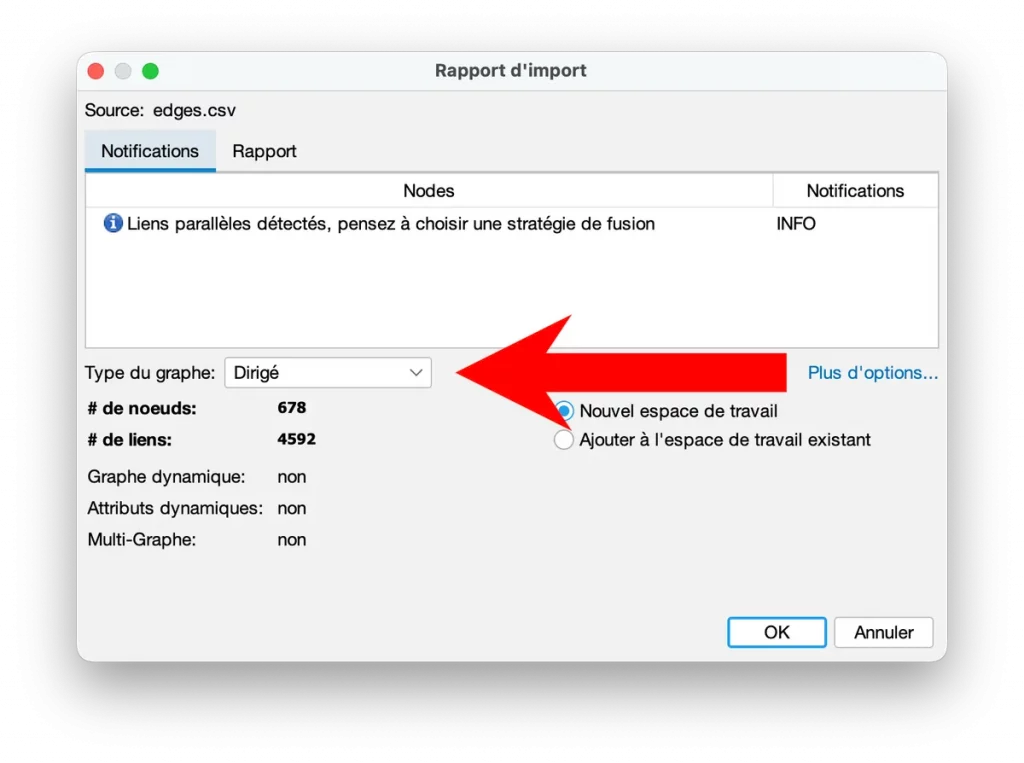
Validez.
Et là… vous venez de charger votre site dans Gephi.
Passer dans Overview (vue d’ensemble) et afficher le réseau
Cliquez sur Overview ou Vue d’ensemble.
Vous devriez voir un amas de points plus ou moins compact. Parfois c’est un plat de spaghettis. C’est normal. Gephi au début, c’est rarement “waouh c’est clair”, plutôt “waouh… c’est le bazar”.
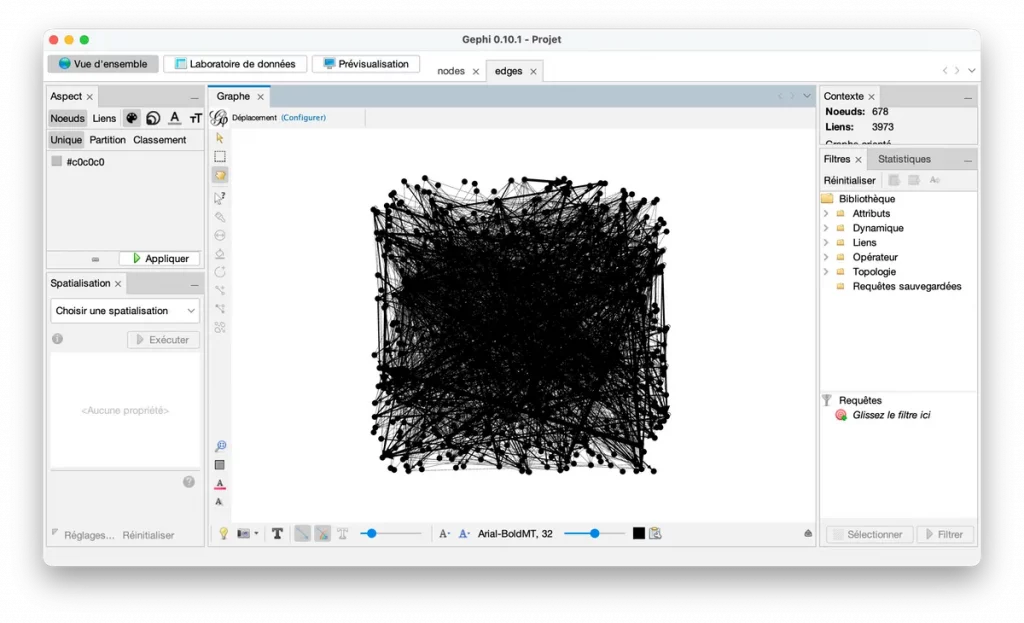
On va ranger tout ça.
Mettre en forme le graphe pour qu’il devienne lisible
Commençons par choisir un layout pour une mise en page automatique.
- À gauche, vous avez une section Layout ou Spatialisation.
Un layout, c’est un algorithme qui pousse les noeuds pour que :
- les pages très liées se rapprochent,
- les pages peu liées s’éloignent.
Pour débuter, essayez :
- ForceAtlas 2 (très utilisé)
- ou Yifan Hu (souvent plus stable sur gros graphes)
Procédure :
- Sélectionnez ForceAtlas 2
- Cliquez sur Run ou Exécuter
- Laissez tourner quelques secondes
- Cliquez sur Stop
Vous verrez le graphe se “déployer” comme un ressort qu’on lâche.
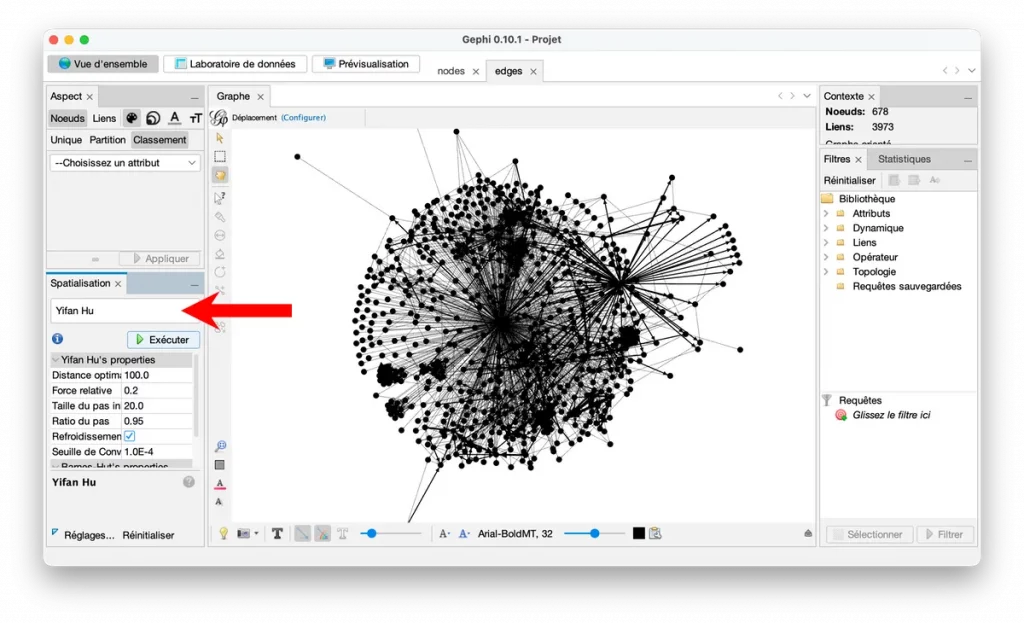
Si ça bouge trop vite, baissez la vitesse (selon votre version Gephi, il y a des réglages). L’objectif n’est pas la perfection, mais une structure globale.
Afficher les labels (titres des pages) sans tout gâcher
En haut, activez Labels.
Problème classique : dès qu’on affiche les titres, c’est illisible.
Solution : on affichera les labels seulement pour les pages importantes, plus tard, avec un filtre ou via Preview. Pour l’instant, gardez-les off ou acceptez un affichage partiel.
Dimensionner les noeuds selon l’importance (le degré)
L’indicateur le plus simple pour commencer : le degré.
- In-degree : nombre de liens entrants (pages qui pointent vers elle)
- Out-degree : nombre de liens sortants (liens qu’elle fait)
Dans l’interface, vous avez généralement un panneau Ranking (ou classement).
- Choisissez Size
- Sélectionnez un critère comme In-Degree
- Appliquez une taille min et max (ex : 5 à 50)
- Appliquez
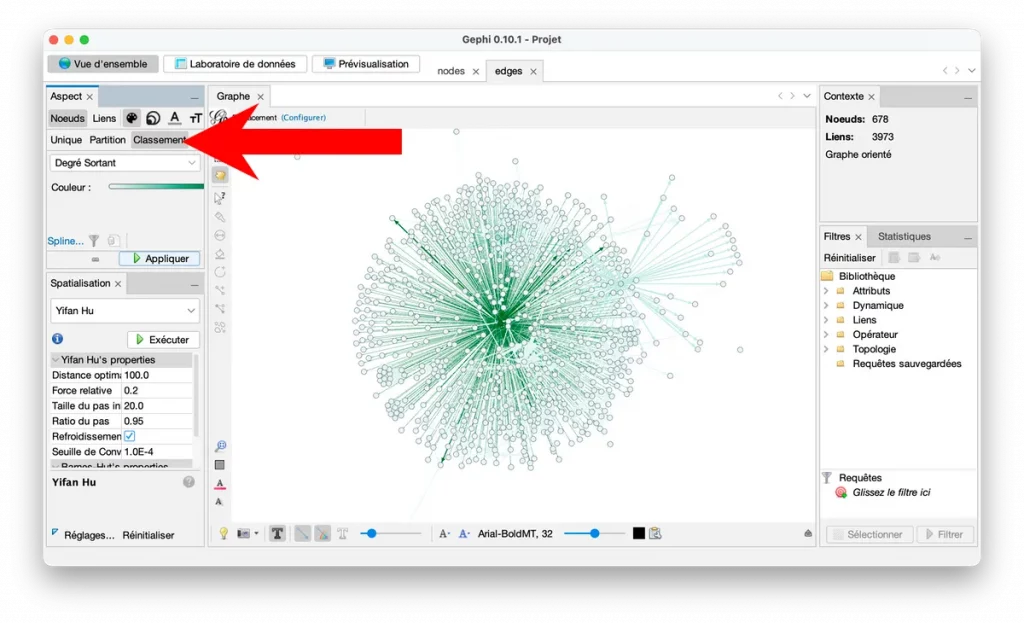
Résultat : les pages qui reçoivent le plus de liens deviennent plus grosses. Visuellement, vous repérez très vite vos pages “piliers” et vos pages un peu délaissées.
Colorer par communautés (Modularity)
C’est l’étape “carte au trésor”.
Dans Fenetres > Statistiques, lancez :
- Modularity ou Modularité
Gephi va détecter des groupes de pages fortement connectées entre elles (souvent des thématiques).
Une fois calculé :
- allez dans Partition (ou “Appearance → Nodes → Color” selon la version)
- choisissez Modularity Class
- appliquez
Vous obtenez des couleurs par “famille de contenus”. Très utile pour voir si votre silo SEO est réel… ou juste un rêve.
Exploiter la carte : pages orphelines et pages sans lien sortant
On arrive au moment où la cartographie du maillage interne devient vraiment actionnable.
Trouver les pages orphelines
Une page orpheline, c’est une page avec 0 lien entrant.
Dans Gephi :
- utilisez un filtre ou un tri sur In-Degree = 0.
Selon votre interface :
- Dans Filters, cherchez “Degree Range” ou “Topology”
- Appliquez sur In-Degree
- Mettez min=0 max=0 (ou un réglage équivalent)
Vous allez voir apparaître les pages isolées. Ce sont souvent :
- des pages importantes mais oubliées dans les menus,
- des vieux contenus plus linkés par personne,
- des pages créées pour un besoin ponctuel,
- parfois des contenus “SEO” qui n’ont pas été intégrés au site.
Et là, vous avez une todo list en 10 secondes : rajouter des liens entrants vers ces pages.
Trouver les pages “cul-de-sac” (sans lien sortant)
Même logique, mais avec Out-Degree = 0.
Ces pages laissent l’utilisateur (et Google) sans direction.
Souvent, une simple section “Pour aller plus loin” en fin d’article suffit à corriger ça.
Exemple concret d’amélioration du maillage interne
Imaginez que votre carte montre :
- une page “Accueil” énorme,
- une page “Blog” énorme,
- mais vos meilleurs tutoriels sont des petits points moyens,
- et votre page “contact” est carrément isolée.
Ce que vous pouvez faire :
- Ajouter dans “Accueil” un bloc “Ressources” avec 5 liens vers les meilleurs tutoriels.
- Dans chaque tutoriel, ajouter 2 liens vers :
- un article plus débutant (pour guider)
- un article plus avancé (pour approfondir)
- Ajouter dans “Blog” une section “Parcours recommandé” (et là, Gephi vous montrera ensuite un graphe plus équilibré).
La cartographie du maillage interne, ce n’est pas “faire des liens au hasard”. C’est construire des routes logiques.
Exporter un rendu propre (Preview)
Quand votre carte vous plaît :
- Allez dans Preview ou Prévisualisation
- Ajustez :
- épaisseur des edges (liens)
- taille des labels (si vous en affichez)
- opacité pour éviter l’effet “mur noir”
- Cliquez sur Refresh ou Rafraichir
- Fichier > Export > PNG/SVG/PDF

Astuce : pour un article de blog, un export en PNG suffit. Pour retravailler l’image dans un logiciel, le SVG est royal.
Quand on parle de SEO sur WordPress, on a souvent tendance à imaginer des réglages, des plugins, des balises… alors que parfois, le vrai problème, c’est juste que votre site ne se “raconte” pas bien à lui-même. La cartographie du maillage interne, c’est un peu comme allumer la lumière dans une pièce où vous rangez depuis des mois “plus tard”. Tout est là, mais tant que vous ne voyez pas la structure, vous faites au mieux… au hasard.
Avec votre export CSV et Gephi, vous venez de gagner une compétence rare : la capacité de voir votre site comme Google le parcourt. Et ce regard-là change tout. Vous ne rajoutez plus des liens parce que “il faut du maillage”, vous les ajoutez parce que vous avez compris où sont les ponts manquants, où sont les impasses, et quels contenus méritent d’être mis au centre du jeu.
👉 Pour aller plus loin, tout comprendre aux Types d’architecture SEO

Fondateur de l’agence Créa-troyes, affiliée France Num
Intervenant en Freelance.
Contactez-moi