Vous avez probablement déjà remarqué que votre plateforme de streaming préférée semble deviner vos goûts avec une précision presque déconcertante. Ou peut-être avez-vous été surpris par la pertinence des publicités qui s’affichent lors de votre navigation. Derrière ces expériences personnalisée se cache des mathématiques appliquées. Plus précisément, des modèles statistiques, une brique fondamentale qui transforme un simple site vitrine en une application web véritablement intelligente et réactive.
- Apprenez à transformer vos données de navigation en fonctionnalités prédictives pour offrir une expérience utilisateur intuitive sur vos projets.
- Découvrez comment intégrer des outils mathématiques modernes directement dans votre flux de travail de développeur pour automatiser des décisions complexes sans code superflu.
- Gagnez en expertise technique en évitant les erreurs de logique classiques qui faussent les analyses et ralentissent les performances de vos applications web.
Dans le monde du développement web, il permet de passer d’un code figé, qui répond toujours de la même manière, à un système capable d’apprendre des données qu’il reçoit. Pour un développeur, maîtriser ces concepts, c’est s’offrir la possibilité de construire des fonctionnalités à forte valeur ajoutée, comme des moteurs de recommandation ou des outils de prédiction de trafic.Préparez-vous à voir votre code sous un tout nouvel angle.
- Comprendre le concept : qu'est-ce qu'un modèle statistique ?
- Les fondations mathématiques : les formules sans la migraine
- Du calcul au code : l'implémentation pratique
- L'importance de la qualité des données
- Les modèles de classification : trier l'information automatiquement
- L'intégration des modèles dans l'architecture web
- Les pièges classiques : quand les chiffres nous trompent
- Optimisation et performances : ne ralentissez pas votre site
- Pourquoi franchir le pas aujourd'hui ?
Comprendre le concept : qu’est-ce qu’un modèle statistique ?
Pour bien débuter, il est essentiel de définir le terme de manière simple. Imaginez qu’un modèle statistique soit une sorte de moule mathématique. Vous lui donnez des données brutes en entrée, souvent issues du comportement de vos utilisateurs, et il vous ressort une tendance ou une probabilité en sortie. C’est une représentation simplifiée de la réalité qui nous aide à prendre des décisions basées sur des faits plutôt que sur des intuitions.

Prenons un exemple concret. Supposons que vous gérez un blog de cuisine. Vous remarquez que lorsque vous publiez une recette de soupe en hiver, elle reçoit énormément de visites, alors qu’en été, elle est ignorée. Un modèle statistique va traduire cette observation en une équation mathématique. Il va établir un lien entre la température extérieure et le nombre de clics. Une fois ce modèle « entraîné » sur vos données passées, il devient capable de prédire le succès d’une future recette en fonction de la météo prévue.
Dans le développement web, on utilise ces modèles pour traiter l’incertitude. Le code classique est binaire : si l’utilisateur clique ici, alors fais ça. Le modèle statistique, lui, apporte de la nuance : si l’utilisateur a consulté ces trois articles, il y a 85 % de chances qu’il soit intéressé par celui-ci. C’est cette nuance qui rend les interfaces modernes si humaines et intuitives.
À quoi cela sert-il concrètement dans votre quotidien de développeur ?
L’utilité des modèles statistiques dans le web est vaste, et elle ne se limite pas aux géants de la Silicon Valley. Même sur un projet de taille moyenne, ces outils peuvent transformer l’expérience utilisateur. L’une des applications les plus courantes est l’analyse du comportement. En observant comment les visiteurs naviguent, vous pouvez identifier des goulots d’étranglement sur votre site. Si le modèle détecte qu’un grand nombre d’utilisateurs abandonnent leur panier à une étape précise, vous savez exactement où intervenir.
Un autre domaine majeur est la personnalisation du contenu. Au lieu d’afficher la même page d’accueil pour tout le monde, vous pouvez utiliser des modèles pour segmenter votre audience. Cela permet de proposer des produits, des articles ou des services qui correspondent réellement aux attentes de chaque visiteur. Cela augmente non seulement la satisfaction de l’utilisateur, mais aussi votre taux de conversion, ce qui est souvent l’objectif ultime de tout site web.
Enfin, n’oublions pas la sécurité. Les systèmes de détection de fraude ou de filtrage de spams reposent entièrement sur des modèles statistiques. Ils comparent une action actuelle (comme une tentative de connexion ou l’envoi d’un message) à des milliers de données précédentes pour juger si l’activité est suspecte ou non. Sans ces calculs en arrière-plan, nos boîtes mail seraient saturées de messages indésirables en quelques minutes.
Les fondations mathématiques : les formules sans la migraine
Pour construire ces modèles, nous devons nous appuyer sur quelques formules. La plus célèbre et la plus accessible pour commencer est la régression linéaire. Son but est de trouver une relation droite entre deux variables. Par exemple, plus un utilisateur passe de temps sur votre site, plus il a de chances d’acheter un produit.
L’équation se présente généralement sous la forme d’une fonction affine :
y = ax + bDans cette formule :
yest ce que nous essayons de prédire (par exemple, le montant du panier).xreprésente la donnée que nous connaissons (le temps passé sur le site).
- Le coefficient directeur
aindique la force de la relation. - L’origine à l’ordonnée
best le point de départ.
Si cela vous semble abstrait, dites-vous simplement que le modèle cherche à tracer la ligne qui passe le plus près possible de tous les points de données que vous avez récoltés.
Il existe aussi des modèles plus complexes, comme la régression logistique, qui ne sert pas à prédire une valeur précise, mais une probabilité d’appartenir à une catégorie. C’est le fameux « oui ou non ».
- Est-ce que cet utilisateur va s’abonner à la newsletter ?
- Est-ce que ce commentaire est un spam ?
Ici, le résultat est toujours compris entre 0 et 1. Ces formules sont les piliers sur lesquels reposent les algorithmes que vous allez bientôt manipuler.
Du calcul au code : l’implémentation pratique
Pour un développeur, la bonne nouvelle est que vous n’avez pas besoin de réinventer la roue. Il existe de nombreuses bibliothèques qui s’occupent des calculs complexes pour vous.
En JavaScript, des outils comme Simple-Statistics ou même TensorFlow.js permettent d’intégrer de l’intelligence directement dans le navigateur. Si vous travaillez plutôt côté serveur avec Python, des librairies comme Scikit-learn sont les standards de l’industrie.

Imaginons que vous vouliez prédire le temps de chargement de votre page en fonction du poids des images que vous y ajoutez. C’est un cas d’école parfait pour appliquer la régression linéaire que nous avons vue plus haut. Au lieu de deviner, vous allez donner à votre script une liste de données passées (le poids en Mo et le temps en secondes). Le modèle va apprendre la corrélation et, la prochaine fois que vous ajouterez une image de 5 Mo, il pourra vous donner une estimation fiable du délai de chargement avant même que l’image ne soit affichée.
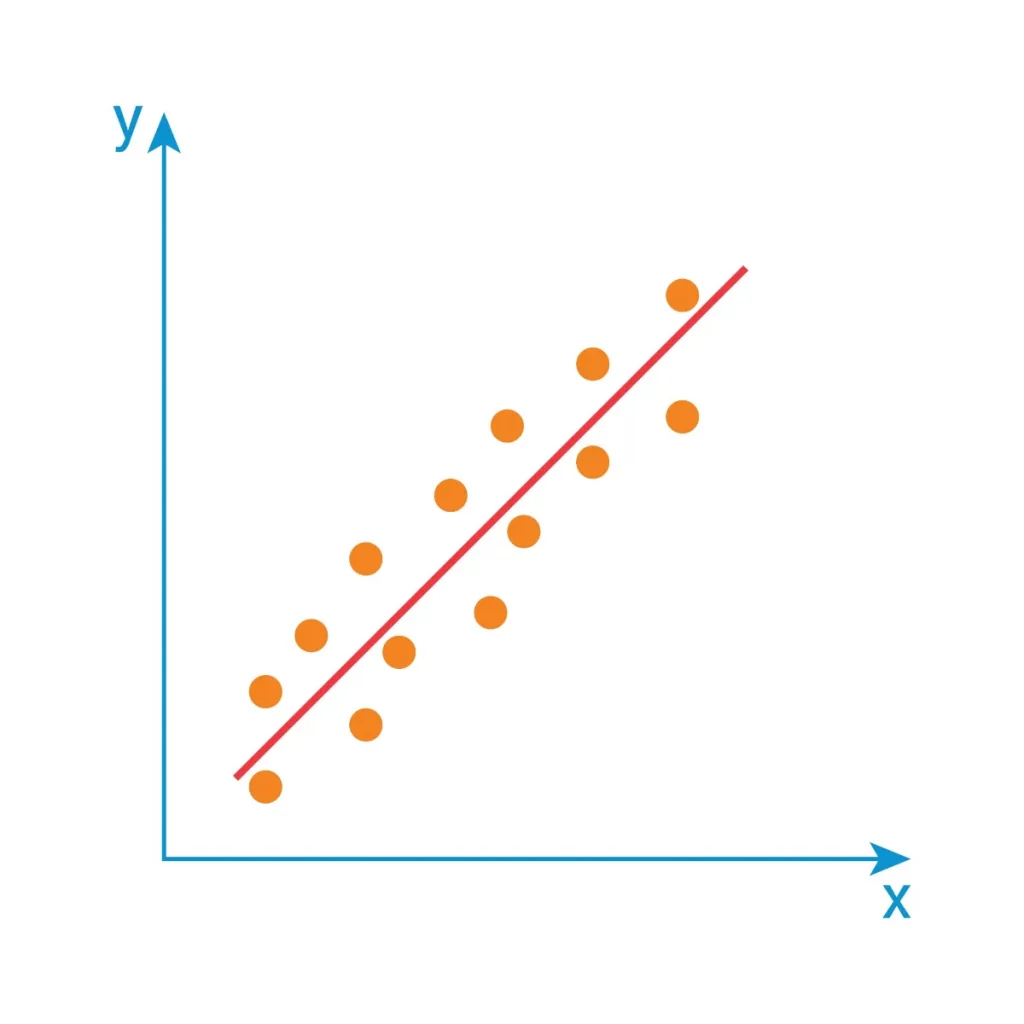
Voici un exemple simplifié en JavaScript pour illustrer comment on pourrait calculer une tendance de base. Supposons que nous ayons une série de données représentant le nombre de pages vues par un utilisateur et son score d’engagement final :
// Données : [pages vues, score d'engagement]
const donneesUtilisateurs = [
[1, 10],
[2, 22],
[3, 35],
[4, 44],
[5, 58]
];
// Fonction simplifiée pour calculer la pente (a) et l'ordonnée (b)
function entrainerModele(data) {
let sommeX = 0, sommeY = 0, sommeXY = 0, sommeX2 = 0;
const n = data.length;
data.forEach(([x, y]) => {
sommeX += x;
sommeY += y;
sommeXY += x * y;
sommeX2 += x * x;
});
const a = (n * sommeXY - sommeX * sommeY) / (n * sommeX2 - sommeX * sommeX);
const b = (sommeY - a * sommeX) / n;
return (x) => a * x + b; // Retourne la fonction de prédiction
}
const predireEngagement = entrainerModele(donneesUtilisateurs);
console.log("Pour 6 pages vues, l'engagement estimé est de :", predireEngagement(6));Dans ce petit bout de code, nous avons codé un mini-moteur de prédiction. C’est la base de ce que l’on appelle le Machine Learning, mais appliqué de manière artisanale et compréhensible. Vous voyez que la logique reste celle d’une fonction classique : on traite une entrée pour obtenir une sortie logique.
Pour aller plus loin, consulter notre Introduction au Machine learning.
L’importance de la qualité des données
C’est ici que je dois vous raconter une petite histoire qui arrive à beaucoup de développeurs débutants dans le domaine. Un ami travaillait sur un algorithme pour un site de livraison de repas. Il voulait prédire quels soirs les clients allaient commander le plus pour ajuster la puissance de ses serveurs en conséquence. Il a nourri son modèle avec des mois de données.
Le premier mois, tout fonctionnait à merveille. Puis, soudainement, un mardi soir, ses serveurs ont planté car ils n’avaient pas anticipé un pic de trafic massif. Pourquoi ? Parce que son modèle ne savait pas qu’il y avait un match de finale de Coupe du Monde ce soir-là. Il avait oublié d’inclure la variable « événements sportifs » dans son équation.

Des formations informatique pour tous !
Débutant ou curieux ? Apprenez le développement web, le référencement, le webmarketing, la bureautique, à maîtriser vos appareils Apple et bien plus encore…
Formateur indépendant, professionnel du web depuis 2006, je vous accompagne pas à pas et en cours particulier, que vous soyez débutant ou que vous souhaitiez progresser. En visio, à votre rythme, et toujours avec pédagogie.
Découvrez mes formations Qui suis-je ?Cette petite mésaventure illustre un point crucial : un modèle statistique ne vaut que par la qualité et la pertinence des données que vous lui donnez. Si vous oubliez un facteur majeur, votre prédiction sera faussée. En tant que développeur, votre rôle n’est pas seulement d’écrire l’algorithme, mais de comprendre le contexte métier pour choisir les bonnes informations à analyser. C’est ce qu’on appelle la sélection des caractéristiques (ou feature engineering).
Les modèles de classification : trier l’information automatiquement
Au-delà de la prédiction de chiffres, le développement web utilise énormément la classification. C’est ce qui permet, par exemple, de catégoriser automatiquement des tickets de support client (urgent, technique, facturation) sans qu’un humain ait à les lire un par un.
Pour cela, on utilise souvent des modèles basés sur les probabilités, comme le classifieur de Naive Bayes. Ce nom peut faire peur, mais le principe est enfantin : on regarde la fréquence des mots dans un texte. Si un message contient les mots « paiement », « facture » et « remboursement », la probabilité qu’il appartienne à la catégorie « facturation » est très élevée.
En tant que développeur web, vous pouvez intégrer cela pour améliorer l’expérience utilisateur. Imaginez un champ de recherche qui, avant même que l’utilisateur ait fini de taper, comprend s’il cherche un produit, un article de blog ou une aide technique, et ajuste les résultats en conséquence. Vous ne codez plus des listes de conditions infinies (si mot = X alors…), vous laissez le modèle statistique peser les probabilités et prendre la meilleure décision.
L’intégration des modèles dans l’architecture web
Maintenant que vous comprenez comment fonctionne la logique, vous vous demandez sûrement où placer ces modèles dans votre architecture. Il y a deux grandes approches. La première consiste à exécuter le modèle côté client (dans le navigateur). C’est idéal pour la confidentialité des données et pour la réactivité, car il n’y a pas d’aller-retour avec le serveur. C’est parfait pour des outils de retouche d’image en ligne ou des suggestions de saisie.
La seconde approche, plus robuste, consiste à héberger votre modèle sur le serveur ou via une API dédiée. Le navigateur envoie les données de l’utilisateur, le serveur effectue le calcul lourd et renvoie la réponse. C’est la méthode privilégiée pour les systèmes de recommandation complexes ou lorsque vous devez comparer les données de l’utilisateur actuel avec celles de millions d’autres.
Des plateformes comme AWS, Google Cloud ou Azure proposent des services qui permettent de déployer ces modèles en quelques clics sous forme d’API REST classiques.
Les pièges classiques : quand les chiffres nous trompent
Dans l’enthousiasme de la nouveauté, on a tendance à vouloir mettre des statistiques partout. Cependant, il existe un phénomène bien connu des développeurs de données appelé le surapprentissage, ou overfitting. Pour faire simple, c’est quand votre modèle apprend tellement bien vos données passées par cœur qu’il devient incapable de gérer la moindre nouveauté. C’est comme un étudiant qui aurait mémorisé les réponses d’un examen blanc, mais qui paniquerait si on changeait un seul chiffre dans l’énoncé de l’examen réel.
Pour éviter cela, la règle d’or est de toujours diviser vos données en deux groupes :
- Un groupe pour l’entraînement (pour que le modèle apprenne)
- Un groupe de test (pour vérifier s’il a bien compris la logique générale).
Si votre modèle affiche une précision de 99 % sur vos données d’entraînement mais seulement 50 % sur des données qu’il n’a jamais vues, c’est que vous avez fait de l’overfitting. Un bon développeur web sait rester humble face aux résultats : il vaut mieux un modèle un peu moins précis mais capable de s’adapter à la diversité des utilisateurs réels.
Un autre point de vigilance concerne les biais. Les statistiques ne sont que le reflet des données que vous leur fournissez.
Si votre base de données ne contient que les habitudes d’utilisateurs parisiens, votre modèle sera probablement très mauvais pour prédire le comportement d’un utilisateur à Montréal ou à Tokyo.
En tant que créateurs, vous avez la responsabilité de veiller à ce que vos modèles soient alimentés par des données variées et représentatives de l’ensemble de votre audience.
Optimisation et performances : ne ralentissez pas votre site
L’intégration de modèles statistiques ne doit jamais se faire au détriment de la performance. Un modèle trop lourd à charger en JavaScript peut faire fuir vos visiteurs avant même qu’ils ne voient votre superbe fonctionnalité de recommandation. C’est là que le talent du développeur entre en jeu pour trouver le juste équilibre.
Si vous utilisez des modèles côté client, privilégiez des bibliothèques légères et n’importez que les fonctions nécessaires. Si les calculs demandent trop de ressources, déportez la logique dans un Web Worker. Cela permet d’effectuer les opérations mathématiques en arrière-plan sans bloquer l’interface utilisateur. Rien n’est plus frustrant pour un internaute qu’une souris qui saccade pendant que le site « réfléchit ».
Côté serveur, pensez à la mise en cache. Si vous avez calculé des prédictions pour un profil utilisateur spécifique, il est souvent inutile de recalculer le modèle à chaque rafraîchissement de page. Stockez les résultats temporairement dans une base de données rapide comme Redis. Votre serveur vous remerciera, et votre facture d’hébergement aussi.
Pourquoi franchir le pas aujourd’hui ?
Vous pourriez vous dire que tout cela est bien complexe pour un simple site web. Pourtant, la barrière à l’entrée n’a jamais été aussi basse. Aujourd’hui, un développeur qui comprend les modèles statistiques possède un avantage compétitif énorme. Il ne se contente pas d’aligner des balises HTML et des styles CSS ; il construit des outils qui apportent une véritable intelligence d’affaires.
C’est une compétence qui vous permet de dialoguer avec les équipes de marketing, les data scientists et les chefs de produit avec une vision transversale. Vous devenez celui qui est capable de transformer une intuition abstraite en une fonctionnalité technique concrète et mesurable. C’est cette capacité à faire le pont entre la donnée et l’expérience utilisateur qui définit les meilleurs profils techniques actuels.
N’ayez pas peur de commencer petit. Vous n’avez pas besoin de créer le prochain algorithme de Google dès demain. Commencez par une simple régression pour estimer un temps de lecture, ou un petit classifieur pour trier des retours utilisateurs. C’est en forgeant que l’on devient forgeron, et c’est en codant des statistiques que l’on devient un développeur de nouvelle génération.
Maîtriser les modèles statistiques, c’est un peu comme apprendre à lire entre les lignes du web. Vous ne voyez plus seulement des clics et des formulaires, mais des flux de probabilités et des opportunités d’amélioration. Nous avons vu ensemble que, derrière les formules intimidantes, se cachent des concepts logiques qui, une fois traduits en code, deviennent des outils d’une puissance incroyable pour personnaliser et sécuriser vos applications.
Ce voyage dans le monde des mathématiques appliquées n’est que le début. Le développement web évolue vers une fusion de plus en plus étroite avec la science des données. En intégrant ces notions dès maintenant dans votre flux de travail, vous ne vous contentez pas de suivre la tendance, vous prenez une longueur d’avance sur les standards de demain. Alors, ouvrez votre terminal, récupérez quelques données de test, et commencez à transformer vos lignes de code en un système capable de prédire l’avenir.

Fondateur de l’agence Créa-troyes, affiliée France Num
Intervenant en Freelance.
Contactez-moi